Introduction
Definition of Overfitting and Underfitting
In the fascinating world of machine learning, two critical concepts stand out: overfitting and underfitting. Understanding these terms is crucial for anyone looking to build effective models.
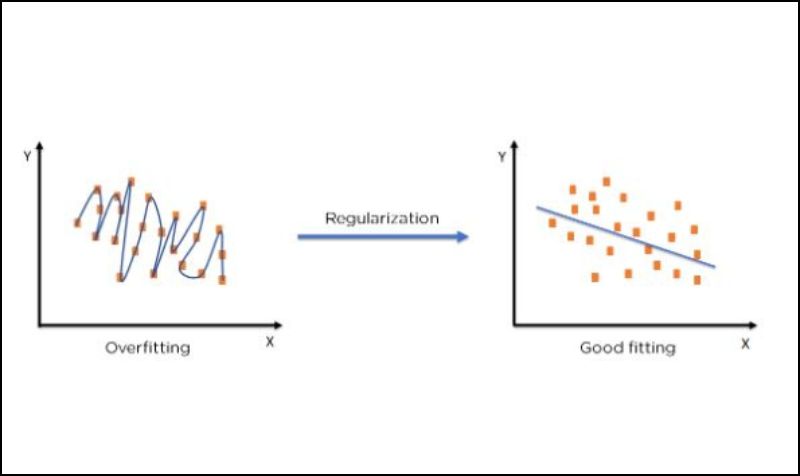
Overfitting occurs when a model captures noise or anomalies in the training data instead of the underlying pattern. It performs excellently on training data but poorly on unseen data, leading to a significant drop in generalization.
On the other hand, underfitting happens when a model is too simplistic to capture the data’s intricacies. Such models neither perform well on training nor validation data, indicating that they have not learned enough from the given dataset.
Here’s a quick summary:
- Overfitting: Model learns too much from the training data, failing to generalize.
- Underfitting: Model learns too little, resulting in poor performance on both training and unseen data.
Significance of Addressing Overfitting and Underfitting in Machine Learning
Addressing the challenges of overfitting and underfitting is paramount for achieving accuracy and reliability in machine learning models. It’s not just about having a high accuracy score on the training data; it’s about building models that can predict outcomes successfully in real-world applications.
Consider a scenario where a company wants to predict customer behavior using machine learning. If the model is overfitted, it might suggest actions based on peculiar past customer behaviors that don’t apply to future customers. Alternatively, if underfitted, it might offer broad recommendations that fail to address individual customer needs.
To summarize, recognizing and mitigating overfitting and underfitting can lead to:
- Improved model generalization
- Better decision-making processes based on accurate predictions
- Enhanced business outcomes by aligning strategies with the actual patterns in data
By understanding overfitting and underfitting, practitioners can significantly improve their machine learning projects, making this knowledge essential for anyone interested in the field.
.jpg)
Overfitting in Machine Learning
Understanding Overfitting
As we delve deeper into the nuances of machine learning, one of the primary issues that arises is overfitting. Picture this: you’ve trained your model on a dataset and it’s performing wonderfully during training—perhaps with a 95% accuracy rate! However, when you apply it to new, unseen data, its performance plummets to a mere 60%. This is the classic sign of overfitting, where the model has learned the training data too well, including its noise and outliers, rather than learning the underlying patterns.
Factors Contributing to Overfitting
Several factors can lead to overfitting, and understanding them is key to building robust models. Here are a few common culprits:
- Complex Models: Using complex algorithms with many parameters can lead to models that are too flexible, making it easy for them to fit the training data too closely.
- Insufficient Data: When the training dataset is small, models can latch onto noise in the data rather than broader trends. It’s like trying to learn a song by only hearing a few notes—there’s much more to capture!
- Inadequate Regularization: Regularization techniques, which penalize excessively complex models, help mitigate overfitting. Without them, your model may become overly tailored to the training data.
Effects of Overfitting on Model Performance
The consequences of overfitting can be quite dire. A model that overfits will deliver:
- Poor Generalization: As mentioned earlier, the model won’t perform well on real-world data, which is a crucial aspect for any practical application.
- Misleading Metrics: High accuracy on training data can create a false sense of security, leading to suboptimal business decisions based on inaccurate predictions.
To illustrate, imagine a financial institution using an overfitted model to assess credit risk. It might flag many safe applicants as high-risk, negatively affecting their business and reputation. Recognizing and addressing overfitting is, therefore, imperative for making successful predictions and informed decisions in machine learning endeavors.
Underfitting in Machine Learning
Understanding Underfitting
Moving from the complexities of overfitting, let’s explore the counterpart known as underfitting. When a model is underfitted, it means that it hasn’t captured the underlying trends in the data at all. Imagine trying to fit a straight line to a set of points that clearly form a curve; this simplistic approach fails to account for the nuances in the data. As a result, the model performs poorly not only on training data but also on unseen data—often yielding an accuracy rate that leaves much to be desired.
Reasons Behind Underfitting Occurrence
Several factors contribute to underfitting, and being aware of these can prevent your models from missing the mark:
- Too Simple Models: Using models that are too simplistic, such as linear regression on complex datasets, can lead to a lack of necessary complexity to learn from the data.
- Insufficient Training: When a model isn’t trained long enough or with enough data, it can fail to grasp the essential patterns, much like studying a language for just a week before a big test.
- Excessive Regularization: While regularization is a useful tool to combat overfitting, too much of it can restrict a model’s capability to learn adequately.
Impacts of Underfitting on Model Accuracy
The impacts of underfitting are notable and often detrimental:
- Low Accuracy on All Datasets: Underfitting leads to poor performance across both training and validation datasets, marking a significant gap between expectations and results.
- Failure to Identify Patterns: Crucial insights may be left undiscovered, impacting decision-making processes. For instance, a healthcare model attempting to diagnose diseases with an underfitted algorithm may overlook key symptoms, risking patient outcomes.
In summary, understanding and addressing underfitting are essential for creating accurate predictive models in machine learning. Recognizing the signs of underfitting ensures that practitioners can take corrective action before significant misunderstandings arise in data interpretations and decisions.
Balancing Overfitting and Underfitting
Techniques to Mitigate Overfitting
Having explored the nuances of overfitting and underfitting, let’s delve into effective techniques for striking that delicate balance. The aim is to create models that generalize well to new data without falling prey to overfitting.
Here are some tried-and-true methods:
- Regularization: Techniques like L1 and L2 regularization add a penalty for larger coefficients, helping to keep the model simpler and less prone to overfitting.
- Cross-Validation: Utilizing k-fold cross-validation ensures that the model is validated on multiple subsets of the data, giving a more reliable estimate of performance.
- Pruning: In decision trees, pruning removes branches that have little significance, reducing the model’s complexity and helping it generalize better.
- Early Stopping: During training, monitor validation loss and stop training once it begins to increase, preventing the model from learning noise inherent in the training data.
Approaches to Handle Underfitting
Now, when it comes to underfitting, here are practical approaches to detect and mitigate this problem:
- Increase Model Complexity: If you’re using a simple model, consider trying more complex algorithms that can capture more intricate patterns in the data.
- Feature Engineering: Sometimes, the model needs more informative features. Adding or transforming features can significantly impact the model’s performance.
- Reducing Regularization: If excessive regularization has been applied, relaxing these constraints may allow the model to learn more effectively.
Finding the Right Model Fit
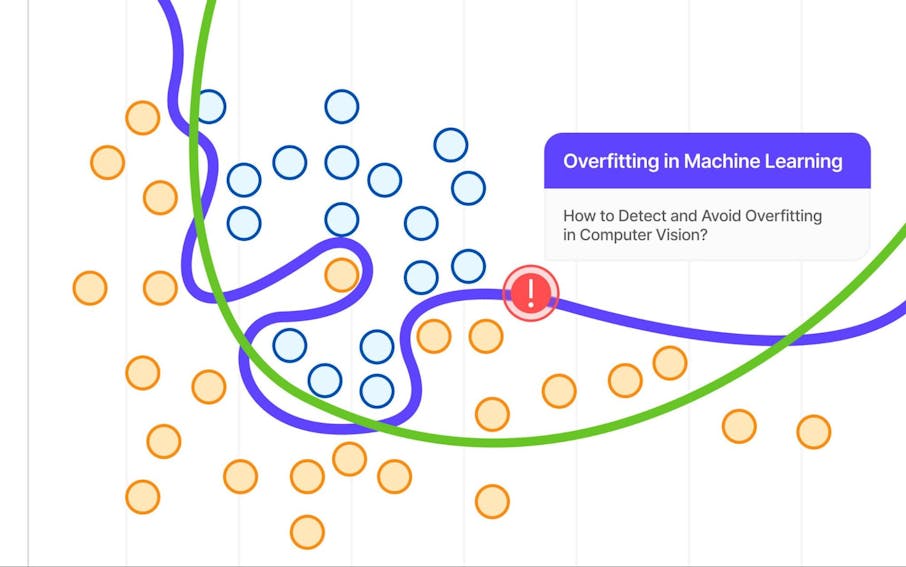
Achieving the right balance between overfitting and underfitting is like finding a perfect tune on a radio. It requires a combination of the right model, appropriate data, and iterative testing. Tools like Grid Search can help in hyperparameter tuning, ensuring you find the ideal settings for your model.
Ultimately, the goal should be to keep iterating until you find that sweet spot where your model neither overfits nor underfits, allowing for robust and reliable predictions. As each project provides various challenges, staying flexible and open to adjustments throughout the modeling process is key to success in the ever-evolving realm of machine learning.
Model Evaluation and Validation
Cross-Validation Methods
Continuing our journey toward building robust machine learning models, let’s focus on the critical aspect of model evaluation and validation. One of the most effective techniques for assessing a model’s performance is cross-validation. This method entails partitioning the dataset into multiple subsets, or folds, allowing the model to be trained and validated on different data portions.
- K-Fold Cross-Validation: Arguably the most commonly used, it divides the dataset into K equal parts. The model then trains on K-1 parts and validates on the remaining part, iterating this process K times until every sample has been used for validation.
- Stratified K-Fold: Particularly useful for classification tasks, it preserves the percentage of samples for each class in each fold, ensuring balanced training and validation sets.
By employing cross-validation, you get a more reliable estimate of model performance across different datasets, which helps in fine-tuning your model’s hyperparameters.
Performance Metrics for Model Assessment
Once you’ve validated your model, it’s essential to assess its performance using appropriate metrics. Here are some commonly used metrics:
- Accuracy: The overall correctness of the model, calculated as the ratio of correctly predicted instances to the total instances.
- Precision and Recall: Particularly important in classification tasks where false positives or false negatives can significantly impact business decisions.
- F1-Score: A balance between precision and recall, especially useful when dealing with imbalanced datasets.
Selecting the right performance metrics ensures you understand your model’s strengths and weaknesses, guiding subsequent optimization efforts.
Importance of Validation in Preventing Overfitting and Underfitting
Validation serves as a guardian in your model-building journey. By incorporating robust evaluation techniques, you can effectively prevent both overfitting and underfitting.
For example, consistently checking validation accuracy during training helps in spotting potential overfitting early. On the other hand, iterative feature evaluations can reveal whether the model isn’t capturing essential patterns, thus addressing underfitting.
In summary, robust model evaluation and validation practices not only enhance the credibility of your machine learning model but also ensure a more reliable output in practical applications. By investing time in this phase, you pave the way for achieving the desired model generalization that effectively meets real-world demands.

Real-World Examples and Case Studies
Overfitting Case Study
Creating a powerful model is exciting, but as many have learned, overfitting can create hidden pitfalls. Take the case of a startup developing a facial recognition algorithm. Utilizing a highly complex deep learning model, the team achieved outstanding accuracy rates of over 98% on their test dataset. However, when they attempted to deploy the model in real-world applications, the accuracy dropped to below 70%.
- What went wrong? The model had memorized the training images, capturing noise and unique features specific to the training dataset rather than general facial characteristics.
This scenario highlights the importance of regularization techniques, cross-validation, and maintaining a simpler model when necessary.
Underfitting Case Study
On the flip side, consider a retail organization attempting to predict customer purchasing behavior. They chose a linear regression model for this task. Given the complexity of customer behavior influenced by numerous factors, the model consistently underperformed, yielding predictions that failed to reflect actual sales trends.
- Issues Faced:
- The simplistic approach didn’t account for interaction effects between features, nor did it capture nonlinear relationships in the data.
- Insufficient training led to a failure in successfully identifying patterns in customer behavior.
Ultimately, this underfitting demonstrated the need for using more sophisticated models and engaging in comprehensive feature engineering.
Lessons Learned and Recommendations
These case studies offer valuable insights into the world of machine learning. Here are key lessons learned:
- Balance Complexity: Strive for models that are appropriately complex for your data while avoiding unnecessary intricacies.
- Iterate and Validate: Regularly evaluate your model using validation techniques to ensure its robustness across different datasets.
- Feature Engineering is Key: Invest time in crafting informative features that can greatly enhance model performance.
By learning from both overfitting and underfitting scenarios, practitioners can develop more reliable and effective machine learning models, paving the way for successful applications in the real world.
Future Trends and Challenges
Advancements in Overfitting and Underfitting Prevention
As we look to the future of machine learning, there are promising advancements aimed at preventing overfitting and underfitting that can significantly enhance model performance. Notably, techniques such as automated machine learning (AutoML) are emerging, enabling non-experts to design and fine-tune models effectively.
- Meta-Learning: This advanced approach employs algorithms that learn how to learn, optimizing model selection and hyperparameters based on previous tasks. By continuously learning from past experiences, these algorithms can make informed decisions to balance model complexity and learning efficiency.
- Regularization Techniques: Enhanced regularization methods, including dropout techniques in neural networks, help mitigate overfitting by probabilistically dropping neurons during training, ensuring the model doesn’t become too reliant on any single pathway.
Emerging Technologies in Model Generalization
Emerging technologies are also revolutionizing model generalization. For instance, transfer learning allows practitioners to leverage pre-trained models (like BERT or ResNet) on related tasks with limited data. This not only improves generalization but also reduces the risk of overfitting since these models have been trained on vast datasets.
- Federated Learning: This innovative approach enables models to be trained across multiple decentralized devices, keeping data localized while still improving performance. This reduces data overfitting risks tied to centralized datasets.
Challenges in Addressing Overfitting and Underfitting in Complex Models
However, these advancements do come with their own set of challenges. As machine learning models grow increasingly complex, the risk of both overfitting and underfitting rises in tandem.
- High Dimensionality: Managing feature sets in high-dimensional data can lead to difficulties in determining the right balance between model complexity and generalization.
- Interpretability: Complex models may become black boxes, making it harder for data scientists to understand where a model goes wrong and to address the issues of underfitting or overfitting effectively.
To navigate this ever-evolving landscape, machine learning practitioners must remain adaptable and continue to explore these advancements while being mindful of potential challenges. By staying at the forefront of technology, they can ensure robust and reliable models that cater to future demands.
Conclusion
Recap of Overfitting and Underfitting Concepts
As we wrap up our exploration of overfitting and underfitting, it’s essential to reiterate the core concepts we’ve discussed. Overfitting occurs when a model learns the training data too intimately, capturing noise rather than underlying patterns, resulting in poor performance on unseen data. In contrast, underfitting arises when a model is too simplistic, failing to capture essential relationships within the data, thus underperforming on both training and validation datasets.
Both of these challenges can severely hinder the effectiveness of machine learning models, making it crucial for practitioners to recognize their signs and understand their implications.
Key Takeaways for Effective Machine Learning Model Building
To navigate the complex landscape of machine learning more successfully, here are some key takeaways:
- Balance is Key: Strive to find the right model complexity. Neither too simple nor too convoluted should prevail; both can lead to significant performance issues.
- Leverage Cross-Validation: Utilize various cross-validation techniques to ensure that your model is capable of generalizing well across different datasets.
- Continuous Learning: Stay updated with the latest advancements in model training and evaluation techniques, such as automated machine learning and transfer learning.
- Validate and Test Thoroughly: Engage in thorough validation using appropriate performance metrics to pave the way for reliable and robust models.
- Iterate and Improve: Embrace an iterative approach, allowing you to refine your models continuously based on performance feedback.
By integrating these principles into their work, machine learning practitioners can construct models that not only meet current demands but are also adaptable for future challenges. In the rapidly evolving field of machine learning, being proactive and aware of both overfitting and underfitting will empower you to create effective, reliable solutions that drive meaningful results.
