
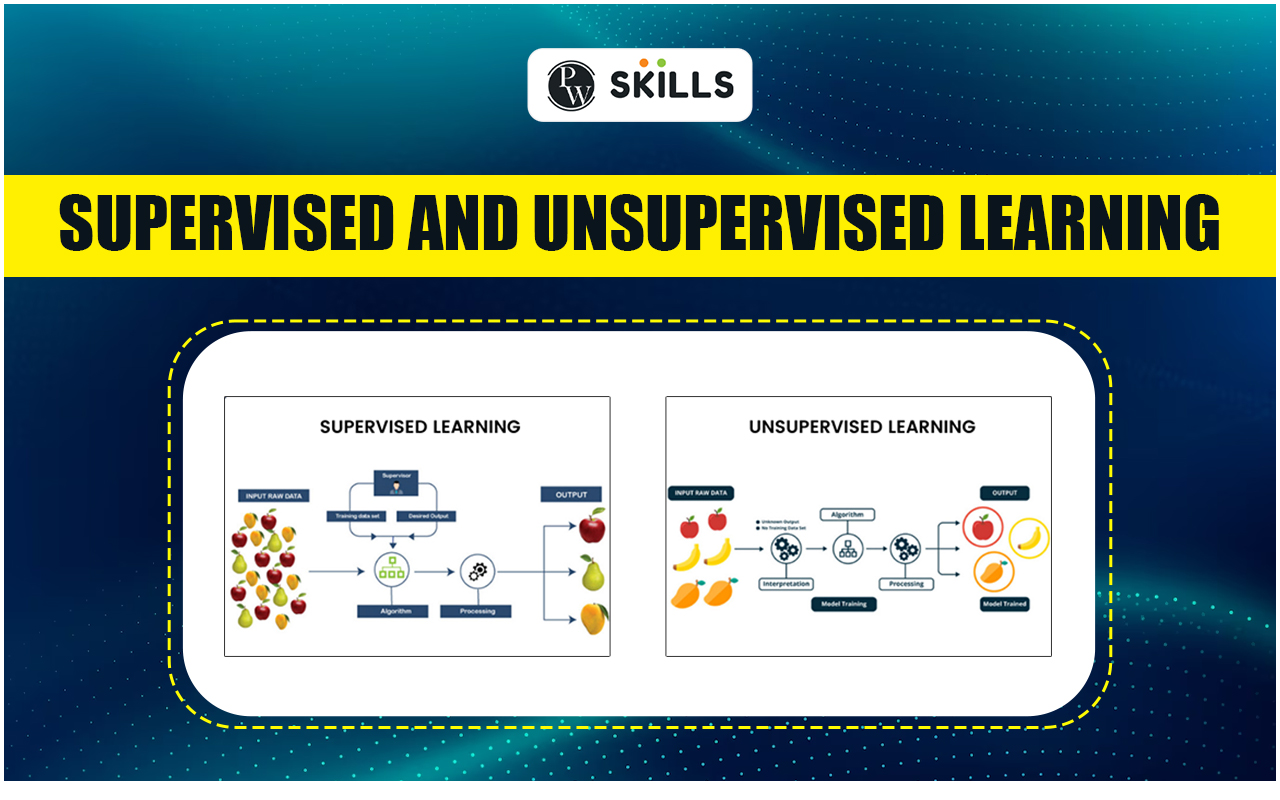
Introduction
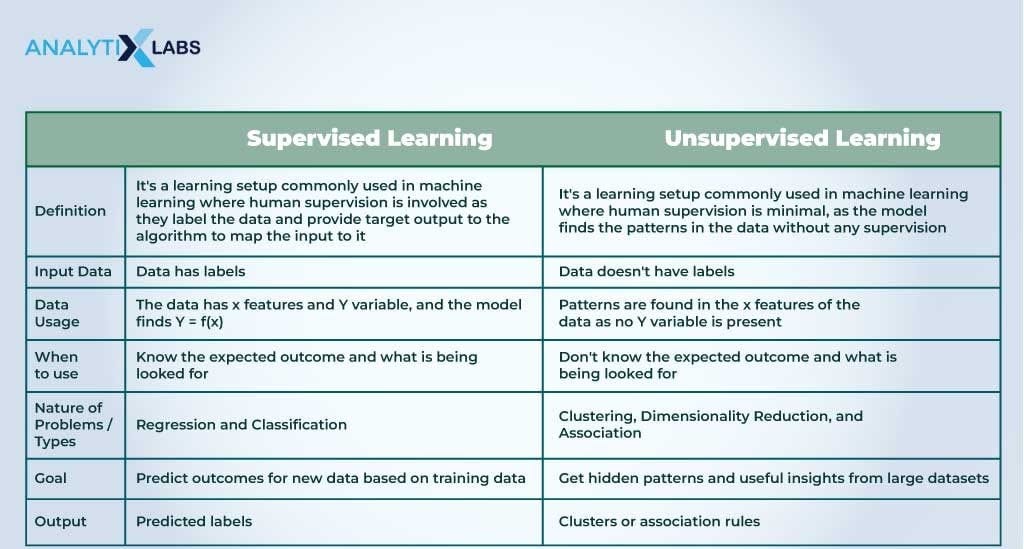
Definition of Supervised Learning
Supervised learning is a type of machine learning where the model is trained on a labeled dataset. In this scenario, the input data is paired with the correct output. Think of it as a teacher guiding students through a lesson, providing answers to every practice question. For example, imagine training a model to recognize images of cats and dogs. Each image would come with an accompanying label, either “cat” or “dog,” allowing the model to learn and predict outcomes.
Definition of Unsupervised Learning
On the other hand, unsupervised learning is like an art class without a teacher. Here, the model operates on datasets without labeled outcomes. It explores patterns and groupings within the data on its own. For instance, consider a scenario where a model analyzes a collection of customer behaviors. It clusters customers into different segments based solely on their purchasing habits, discovering insights without any predefined categories.
This distinction lays a fundamental groundwork for understanding how these two approaches operate in the fascinating world of machine learning.
The Differences Between Supervised and Unsupervised Learning
Training Data Requirement
When diving deeper into the world of machine learning, one of the first contrasts between supervised and unsupervised learning is their training data requirements. Supervised learning relies on labeled datasets, which can be time-consuming and costly to create. Here, the model learns from examples that include both the input and the desired output.
In contrast, unsupervised learning thrives on unlabeled data. This means it can analyze larger datasets without needing extensive input. Imagine organizing your closet: supervised learning would require you to label each item, while unsupervised learning would help you categorize everything based on style or color without guidance.
Target Variable Consideration
The next major difference is the consideration of a target variable. In supervised learning, a target variable exists. For example, predicting house prices involves understanding various influencing factors like the number of rooms and location. Each input correlates with a known outcome.
Unsupervised learning lacks this structure. Take customer segmentation as an example; the algorithm groups customers by behavior, but there’s no specific target variable guiding it.
Output Prediction
Supervised learning focuses on output prediction by establishing a direct relationship between input and expected output. Think of it as a quiz where you know the answers beforehand. In unsupervised learning, the model seeks to uncover hidden structures or patterns in the data and doesn’t produce predictions on specific outputs.
Applications in Real Life
These learning approaches manifest in numerous real-life applications:
- Supervised Learning:
- Spam detection in emails
- Medical diagnosis based on symptoms
- Unsupervised Learning:
- Market basket analysis for retailers
- Anomaly detection in network security
Understanding these differences not only sharpen one’s grasp of these methodologies but also emphasizes their unique strengths in various fields!
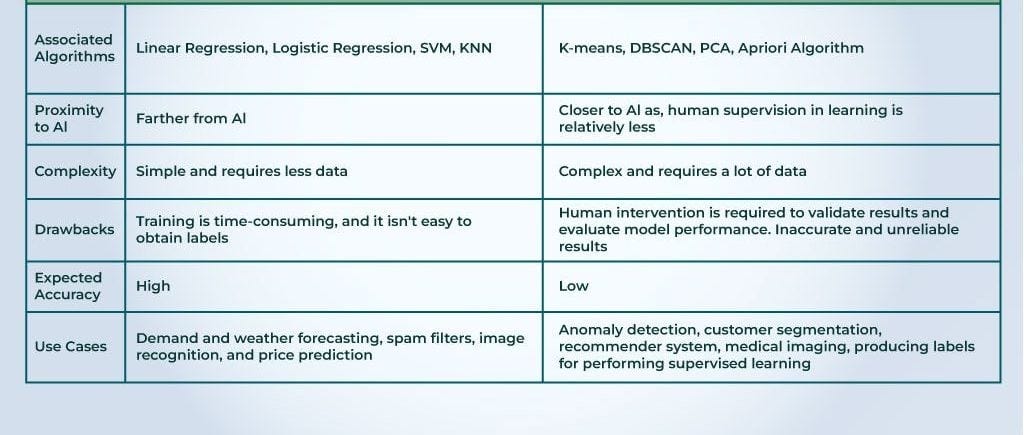
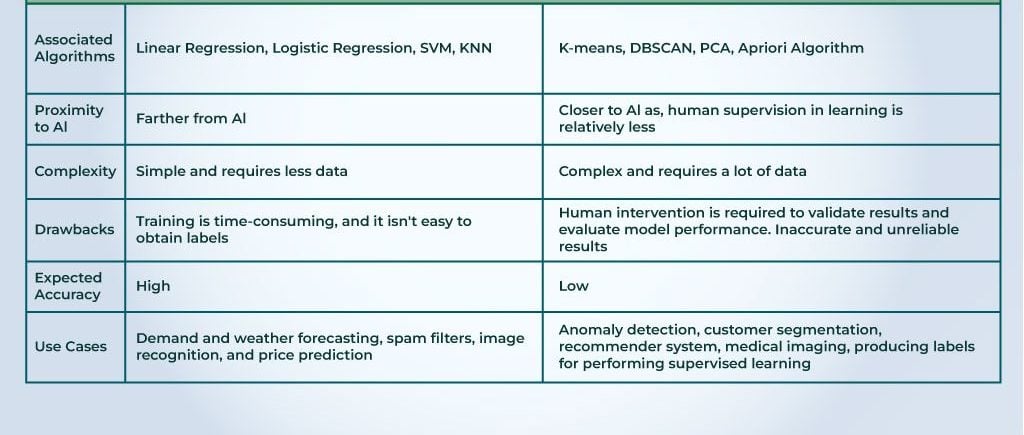
Common Algorithms Used in Supervised and Unsupervised Learning
Supervised Learning Algorithms
As we delve deeper into machine learning, it’s essential to recognize the common algorithms that drive supervised and unsupervised learning. Starting with supervised learning, two algorithms stand out for their effectiveness and versatility:
Linear Regression
Linear regression is a foundational algorithm often used for predictive modeling. It establishes a relationship between input variables and a continuous output. Imagine you’re predicting sales based on advertising spend; linear regression can help identify how much sales increase with each dollar spent.
Support Vector Machines (SVM)
Support Vector Machines (SVM) take a more complex approach by finding the hyperplane that best separates different classes in high-dimensional space. Think of SVM as drawing the best line in a scatterplot to distinguish between cats and dogs. It’s widely used in text classification and face recognition.
Unsupervised Learning Algorithms
Switching gears to unsupervised learning, we encounter a couple of powerful algorithms that help unveil hidden patterns without labeled outcomes.
K-Means Clustering
K-means clustering is a popular algorithm used for grouping data into distinct clusters. For example, brands can use K-means to categorize their customers based on purchasing behavior, identifying core segments to tailor marketing strategies.
Hierarchical Clustering
Hierarchical clustering builds tree-like structures to depict relationships within the data. This is especially helpful when visualizing complex datasets, as it allows users to see how individual data points relate at different levels. Think of it as creating an organizational chart; it helps users understand connections and groupings at a glance.
Both supervised and unsupervised learning algorithms play a critical role in machine learning applications, making the landscape richly diverse and fascinating!
Evaluation Metrics in Supervised and Unsupervised Learning
Supervised Learning Metrics
After understanding the algorithms, it’s crucial to assess their performance using specific evaluation metrics that highlight their effectiveness.
Accuracy
One of the most straightforward metrics is accuracy, which measures the proportion of correct predictions made by the model out of all predictions. However, it’s essential to be cautious with accuracy, especially in imbalanced datasets where one class is more prominent than another.
Precision and Recall
Next, we have precision and recall. Precision answers the question, “Of all positive predictions, how many were actually correct?” Recall, on the other hand, asks, “Of all actual positives, how many did we correctly identify?” These metrics are particularly useful in contexts like medical diagnosis, where false positives and false negatives can have significant consequences.
F1 Score
The F1 score combines precision and recall into a single metric, providing a balanced view of a model’s performance, especially when dealing with class imbalances.
Unsupervised Learning Metrics
Now, let’s shift gears to unsupervised learning, where evaluation is a bit trickier since there’s no labeled output.
Silhouette Score
The Silhouette score measures how similar an object is to its own cluster compared to other clusters. A higher score indicates well-defined distinct clusters, making it easier to interpret results.
Davies–Bouldin Index
Similarly, the Davies–Bouldin index quantifies the average similarity ratio of each cluster with its most similar cluster. A lower value indicates better clustering, providing insight into the effectiveness of the algorithm used.
By utilizing these evaluation metrics, practitioners can better understand their model’s strengths and weaknesses, ultimately refining their machine learning endeavors!
Challenges and Limitations of Supervised and Unsupervised Learning
Overfitting and Underfitting in Supervised Learning
As we delve deeper into machine learning, it’s essential to recognize the challenges that come with supervised learning. Two primary issues practitioners often encounter are overfitting and underfitting.
- Overfitting occurs when a model learns the training data too well, capturing noise instead of the underlying pattern. Imagine studying for an exam by memorizing answers rather than understanding concepts; you might ace a practice test but struggle with real questions.
- Underfitting, on the other hand, happens when a model is too simplistic to capture the complexities of the data. It’s like trying to fit a brief statement when a detailed explanation is required; the model fails to glean valuable insights, leading to poor performance.
Curse of Dimensionality in Unsupervised Learning
Conversely, unsupervised learning faces its own unique set of challenges, most notably the “curse of dimensionality.”
In high-dimensional spaces, data points become sparse, making it difficult for clustering algorithms to effectively group similar data. This sparsity can also lead to misleading results, as the distance metrics that underpin many algorithms become less meaningful in higher dimensions. For instance, consider how real estate prices may vary across numerous features; it’s challenging to identify patterns when the data is vast and convoluted.
Recognizing these challenges is vital for anyone navigating the fascinating but intricate landscape of machine learning!
Future Trends and Developments in Supervised and Unsupervised Learning
Deep Learning Advancements
Looking ahead, the landscape of machine learning is remarkably dynamic, particularly with the rising trend of deep learning advancements. Deep learning, a subset of machine learning, utilizes neural networks to process vast amounts of data and identify patterns much akin to the human brain. For example, self-driving cars leverage deep learning to process real-time data from multiple sensors, significantly improving their decision-making capabilities.
Some emerging deep learning trends include:
- Improved architectures like transformers for natural language processing.
- Enhanced transfer learning, allowing models trained on one task to adapt to others seamlessly.
Reinforcement Learning Integration
Another exciting avenue is the integration of reinforcement learning (RL), which focuses on making sequential decisions. RL algorithms learn by interaction—rewarding desired outcomes and penalizing mistakes. This paradigm is particularly effective in complex environments such as robotics and game-playing AI systems.
Picture a robot learning to navigate a maze: it tries paths, receives feedback, and optimizes its route over time. This level of adaptability signifies a future where machines can make intelligent, real-time decisions, transforming various industries.
As these advancements evolve, they will undoubtedly reshape both supervised and unsupervised learning, making the future of machine learning an exhilarating journey to follow!
Conclusion
Recap of Key Differences
As we wrap up our exploration of supervised and unsupervised learning, it’s clear that these two approaches offer distinct methodologies tailored for varying tasks. Supervised learning thrives on labeled datasets, relying heavily on target variables to drive predictions. It’s perfect for scenarios where outcomes are well-defined, like email classification or medical diagnosis. In contrast, unsupervised learning shines in identifying patterns and groupings within unlabeled data, making it ideal for market segmentation or clustering similar products.
Importance of Choosing the Right Approach
Choosing the right approach is crucial for achieving the desired results in any machine learning project. Consider the old adage: “If all you have is a hammer, everything looks like a nail.” In the world of machine learning, employing the correct technique can unlock insights or complicate processes unnecessarily.
As organizations continue to leverage these powerful tools, understanding their strengths and limitations will lay the foundation for successful applications in real-world scenarios. So, whether you’re a budding data scientist or a business leader, recognizing the implications of these methodologies is vital for making informed decisions!
