
Introduction
Defining Machine Learning
Machine Learning (ML) is an exciting branch of artificial intelligence that enables computer systems to learn from data and improve their performance over time without being explicitly programmed. Imagine teaching a child how to recognize different animals; with each example, they learn and refine their understanding, akin to how ML systems adapt as they process more information.
Significance of Data Transformation
At the heart of every successful machine learning project lies data transformation. This process involves converting raw data into a format that is suitable for analysis. Think of it like preparing ingredients for a recipe; you wouldn’t bake a cake with whole, unchopped vegetables. Key aspects of data transformation include:
- Cleaning: Removing inaccuracies and handling missing values.
- Normalization: Scaling data to a common range, making it easier to analyze.
- Encoding: Converting categorical variables into numerical formats for model compatibility.
Ultimately, effective data transformation is crucial in transforming data into insightful, actionable knowledge.

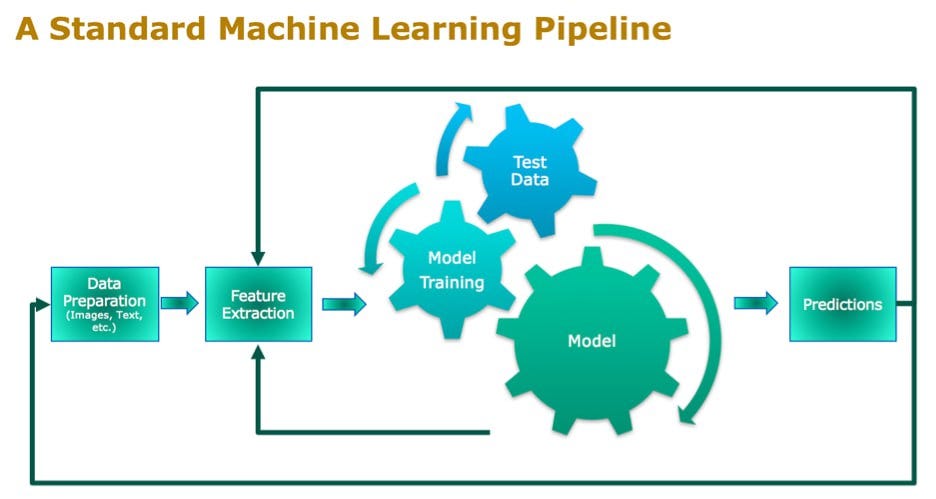
Basics of Machine Learning
Understanding Algorithms
When delving into machine learning, one cannot overlook the importance of algorithms. These are the mathematical models that drive ML, enabling systems to make predictions or decisions based on data. It’s like having various tools in a toolbox; certain tools are better suited for specific tasks. Common algorithms include:
- Linear Regression: Best for predicting continuous outcomes.
- Decision Trees: Excellent for making classifications based on features.
- Support Vector Machines: Effective for high-dimensional spaces.
Data Preprocessing Techniques
Before algorithms can be effectively applied, data must be preprocessed. This step is akin to setting the stage for a performance. Key data preprocessing techniques include:
- Feature Scaling: Adjusting features to a common scale for better convergence.
- Encoding Categorical Variables: Transforming non-numeric categories into numerical forms.
By mastering these basics, individuals can harness the full potential of machine learning.
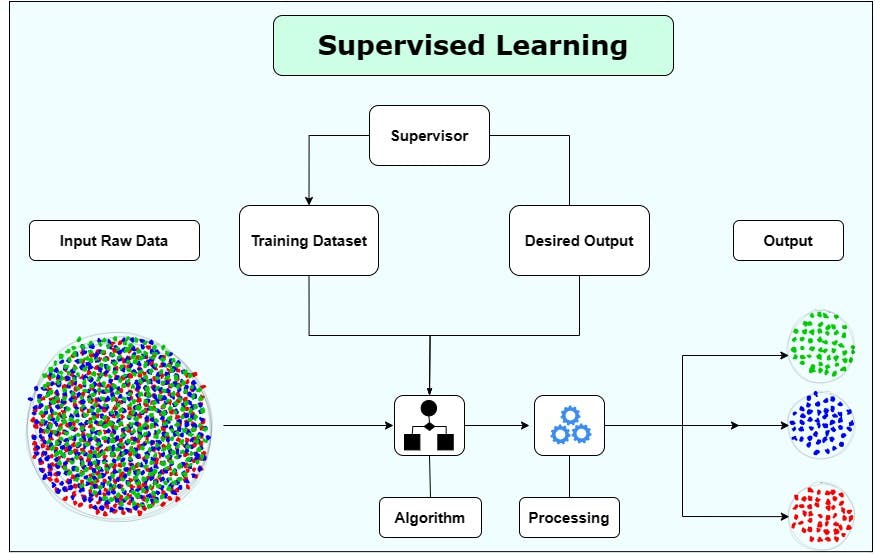
Supervised Learning
Classification and Regression
Supervised learning is a fundamental aspect of machine learning, primarily focusing on training models using labeled data to predict outcomes. There are two main types of supervised learning tasks: classification and regression. Picture a teacher guiding students:
- Classification: Involves categorizing data into predefined classes. For instance, an email filtering system categorizes messages as “Spam” or “Not Spam.”
- Regression: Focuses on predicting continuous values, such as forecasting the temperature for the next week based on historical data.
Training and Testing Data
To ensure model effectiveness, dividing the dataset into training and testing data is essential, much like preparing for an exam. The training data helps the model learn, while the testing data evaluates its performance. A common split is:
- 70% Training Data
- 30% Testing Data
This separation allows for a more accurate measurement of how well the model generalizes to unseen data, ultimately driving better predictions.
Unsupervised Learning
Clustering Methods
Transitioning from supervised to unsupervised learning opens up a different realm of possibilities. Unsupervised learning deals with unlabeled data, allowing algorithms to identify patterns and group similar items together. Think of it as organizing a closet without predetermined categories. One popular technique is clustering. Common methods include:
- K-Means Clustering: Groups data into a specified number of clusters based on proximity.
- Hierarchical Clustering: Creates a tree of clusters, showing the relationships between them.
This method is particularly useful in customer segmentation, allowing businesses to tailor marketing strategies based on group characteristics.
Dimensionality Reduction
Alongside clustering, dimensionality reduction is a key unsupervised technique. It simplifies data by reducing the number of features while retaining essential information. Techniques like Principal Component Analysis (PCA) help visualize complex datasets, making it easier to analyze relationships and uncover hidden insights. For instance, this can transform a multi-dimensional dataset into a two-dimensional plot, enhancing interpretation and decision-making processes.

Deep Learning
Neural Networks
Building on the foundations of machine learning, deep learning takes things a step further with neural networks. Inspired by the structure of the human brain, neural networks consist of interconnected layers of nodes that process data in a highly sophisticated manner. Imagine them as complex road networks, where intersections (neurons) help make decisions based on received information. Common applications include image recognition and natural language processing, proving their versatility and power.
Convolutional and Recurrent Networks
Within deep learning, two notable types of neural networks are Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs).
- CNNs are specifically designed for processing structured grid data like images, utilizing layers that focus on interpreting spatial hierarchies.
- RNNs, on the other hand, are tailored for sequential data, making them ideal for tasks involving time-series data or text, where context matters significantly.
These types of networks substantially enhance the potential for complex data analysis, transforming how we approach problem-solving in various fields.
Evaluating Model Performance
Metrics for Assessment
Once you’ve built your machine learning model, evaluating its performance is crucial to ensure its effectiveness. Just like grading a student’s assignment, metrics provide concrete feedback. Some widely-used metrics include:
- Accuracy: The percentage of correctly predicted instances.
- Precision: The ratio of true positive predictions to the total predicted positives, helping to measure quality.
- Recall (Sensitivity): The ratio of true positives to actual positives, indicating how well the model identifies relevant instances.
Using a combination of these metrics can give a comprehensive view of how well the model performs under various conditions.
Cross-Validation Techniques
To enhance the robustness of your assessment, cross-validation techniques come into play. They allow you to evaluate how the results of your statistical analysis will generalize to an independent dataset. A popular method is k-fold cross-validation, where the data is split into ‘k’ subsets; the model is trained on ‘k-1’ folds and tested on the remaining fold. This process repeats for each subset, providing a more reliable estimate of the model’s accuracy, reducing the risk of overfitting, and ensuring its reliability in real-world applications.
Feature Engineering
Importance in Machine Learning
Transitioning from evaluating model performance, we delve into feature engineering, a vital step in machine learning. Just like a chef selects the best ingredients to create a culinary masterpiece, feature engineering involves selecting and transforming data to enhance model performance. High-quality features can significantly improve a model’s accuracy, making it crucial for success.
For example, in a housing price prediction model, including features like square footage, number of bedrooms, and location can lead to much better results than using raw data alone.
Techniques for Feature Extraction
Several techniques can aid in feature extraction, allowing for more informative input to the model. Key methods include:
- One-Hot Encoding: Transforms categorical variables into binary vectors, suitable for algorithms that require numerical input.
- Polynomial Features: Generates new features by raising existing features to a power, capturing interactions.
- Feature Scaling: Normalizes data to improve convergence for algorithms sensitive to feature ranges.
Effective feature engineering equips models with the depth they need to turn data into powerful insights.
Data Visualization
Exploratory Data Analysis
Continuing from the importance of feature engineering, data visualization plays a pivotal role in interpreting and understanding data better. Through Exploratory Data Analysis (EDA), individuals can visually explore datasets to uncover patterns, trends, and anomalies. It’s like peering through a magnifying glass at data, revealing insights that might otherwise go unnoticed. For example, using scatter plots can help identify correlations between variables, while histograms can show the distribution of data points.
Key activities in EDA include:
- Identifying outliers
- Visualizing distributions
- Understanding relationships between variables
Visualization Tools
To conduct effective EDA, various visualization tools are at your disposal. Popular ones include:
- Matplotlib: A versatile Python library for basic plotting.
- Seaborn: Built on top of Matplotlib, it offers enhanced statistical visualizations.
- Tableau: A powerful platform for interactive and intuitive visualizations.
By utilizing these tools, data scientists can transform complex data into clear visuals, making it easier to share insights with stakeholders and drive informed decisions.

Ethics and Bias in Machine Learning
Addressing Bias in Models
As we navigate the fascinating world of data visualization, it’s crucial to recognize the ethical implications surrounding machine learning, particularly regarding bias in models. Bias can arise from various sources, such as historic prejudices present in the training data or inherent assumptions in the algorithms. For example, a facial recognition system trained primarily on images of certain demographics may perform poorly on others.
To address bias, practitioners can:
- Use diverse datasets to train models, ensuring representation across different groups.
- Implement fairness metrics to evaluate model performance across subgroups.
- Regularly audit models for adverse impact and adjust accordingly.
Ethical Considerations in Data Usage
Beyond bias, ethical considerations in data usage are paramount. Issues such as data privacy, consent, and transparency must be prioritized. Organizations should ensure data is collected responsibly and individuals are aware of how their information is being utilized. Encouraging best practices, like obtaining informed consent and anonymizing sensitive data, builds trust and maintains integrity in machine learning applications. Striking a balance between innovation and ethical responsibility is essential for the continued growth of this powerful technology.

Applications of Machine Learning
Healthcare and Medicine
Building on the pivotal discussions about ethics and biases, the applications of machine learning are vast and transformative, particularly in healthcare and medicine. Imagine a doctor who can quickly diagnose ailments through advanced algorithms. Machine learning assists in analyzing medical images, predicting patient outcomes, and personalizing treatments. For instance, algorithms can analyze thousands of X-rays faster than a radiologist, highlighting potential issues and allowing for timely intervention. Key applications include:
- Predictive Analytics: Anticipating disease outbreaks and patient readmission rates.
- Drug Discovery: Accelerating the search for potential new medications.
Marketing and Business
In the marketing and business realm, machine learning drives smarter decision-making and more effective campaigns. Companies like Netflix and Amazon utilize recommendation systems to tailor experiences based on user behavior, significantly increasing engagement. Important applications encompass:
- Customer Segmentation: Identifying distinct user groups for targeted marketing.
- Sentiment Analysis: Gauging consumer opinions through social media and reviews.
By harnessing the power of machine learning, organizations can not only optimize operations but also enhance customer satisfaction and loyalty.
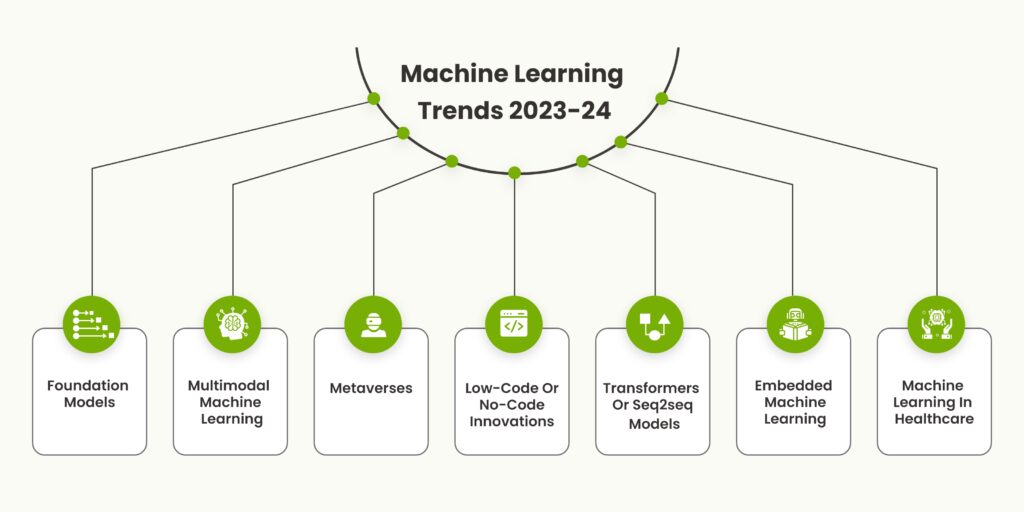
Future Trends in Machine Learning
Advancements in AI
As we wrap up our exploration of machine learning applications, it’s fascinating to look forward to the future trends in machine learning. One notable area of focus is the continued advancements in artificial intelligence. Technologies like federated learning are emerging, enabling models to train on decentralized data without compromising privacy. Additionally, innovations in transfer learning allow models to leverage knowledge from one domain to enhance performance in another, reducing the amount of data required.
- Explainable AI (XAI): Improving transparency in model decisions is becoming increasingly important.
Impact on Various Industries
The impact of these advancements stretches across numerous industries. In finance, machine learning algorithms enhance fraud detection capabilities, while in agriculture, they optimize crop yields through predictive analytics. Other significant areas include:
- Transportation: Autonomous vehicles rely heavily on machine learning for navigation.
- Education: Personalized learning experiences tailor to individual student needs.
As these trends continue to evolve, the potential for machine learning to reshape our world remains immense.
