
Introduction
Importance of Machine Learning Pipelines
In the ever-evolving world of technology, the significance of machine learning pipelines cannot be overstated. These pipelines streamline the process of turning raw data into actionable insights, allowing teams to focus on the development rather than getting bogged down in repeated tasks. For example, when working on a recent project, the team noticed that a well-structured pipeline saved countless hours across data preprocessing to model evaluation.
Key reasons why machine learning pipelines are important include:
- Efficiency: Automates tedious tasks, enhancing productivity.
- Consistency: Ensures reproducibility in results.
- Collaboration: Facilitates teamwork by dividing tasks clearly.
Overview of Machine Learning Pipeline Creation
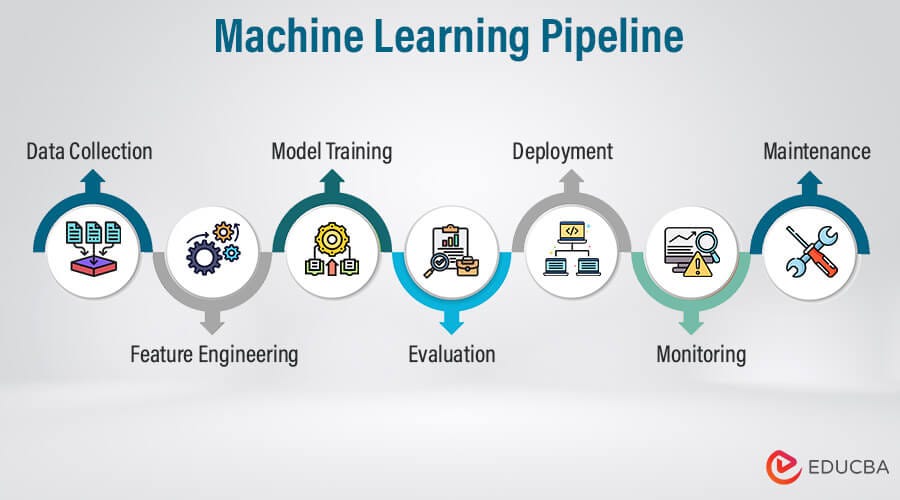
Creating a machine learning pipeline involves several key steps, providing a roadmap for successfully deploying models. It typically includes:
- Data Collection: Gathering relevant datasets.
- Data Preprocessing: Cleaning and preparing the data.
- Model Building: Selecting and training appropriate algorithms.
- Evaluation: Testing model performance and making necessary adjustments.
This structured approach not only maximizes efficiency but also helps teams maintain high standards in their machine learning projects.
Understanding Machine Learning Pipelines
Definition and Purpose
At its core, a machine learning pipeline is a series of steps that automates the process of building machine learning models—from data ingestion to deployment. Think of it as a well-organized assembly line, ensuring that every component flows smoothly into the next. The purpose of this pipeline is to simplify model development, allowing data scientists to work more efficiently and effectively. For instance, when I first started using pipelines in my projects, the clarity it provided in tracking progress truly transformed my workflow.
Components of a Machine Learning Pipeline
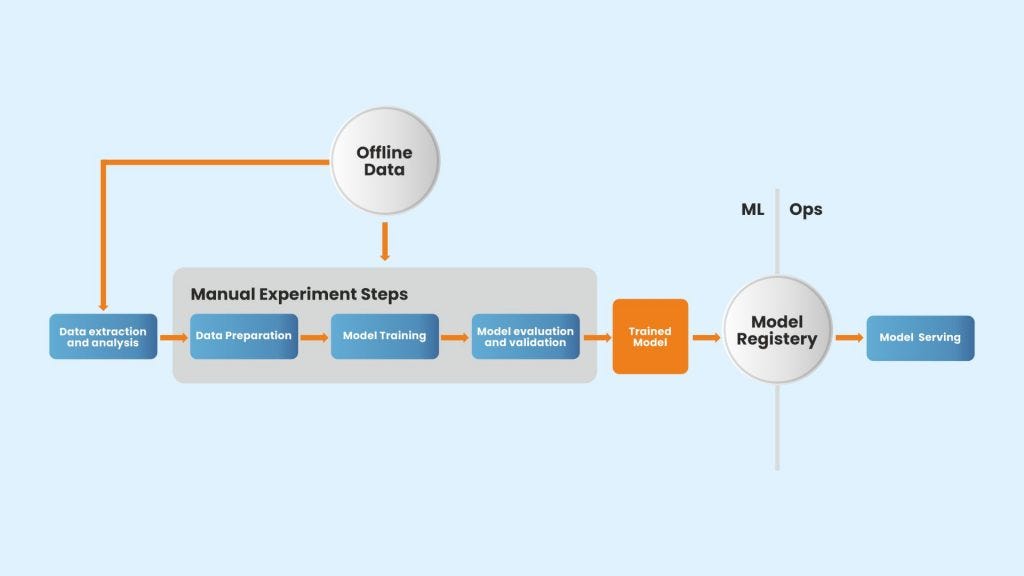
A robust machine learning pipeline consists of several integral components, including:
- Data Ingestion: Importing relevant datasets securely.
- Data Preprocessing: Cleaning, normalizing, and transforming data.
- Feature Engineering: Creating new variables to improve model accuracy.
- Model Training: Applying algorithms to learn from the data.
- Model Evaluation: Assessing the model’s performance using metrics.
- Deployment: Integrating the model into production for real-world use.
Each of these steps plays a vital role in ensuring the success of the machine learning project.
Best Practices for Creating a Machine Learning Pipeline
Data Preprocessing Techniques
Effective data preprocessing is critical for enhancing the model’s performance. Techniques such as normalization, handling missing values, and outlier detection can make a significant difference. For example, when I worked on a financial forecasting model, I made sure to scale the features, which led to much better predictions.
Feature Engineering Methods
Feature engineering is the art of creating new informative features from existing data. This can include:
- Transformations: Applying logarithmic or polynomial transformations.
- Encoding: Converting categorical variables using one-hot encoding.
In one of my projects, deriving interaction terms helped boost the model’s predictive power.
Model Selection and Training
Choosing the right model is paramount. Utilizing cross-validation techniques can help ensure that your selections are robust. I recall conducting a thorough comparison of multiple algorithms, which enabled me to choose the best-performing one.
Hyperparameter Tuning
Hyperparameter tuning allows you to refine your model settings for optimal performance. Techniques like grid search and random search are popular methods. It’s crucial not to skip this step, as I’ve seen substantial improvements in accuracy from simply adjusting a few parameters.
Model Evaluation and Deployment
Once the model is trained, thorough evaluation is essential. Employing metrics such as accuracy, precision, and recall can provide insights into its performance. Afterward, deploying the model into a production environment requires careful attention to ensure it integrates smoothly and performs consistently. Remember, a well-structured pipeline can make this process seamless and impactful!
Automation and Scalability in Machine Learning Pipelines
Tools and Frameworks for Automation
In the realm of machine learning, automation is essential for enhancing efficiency and reducing human error. There are several powerful tools and frameworks available that can automate various stages of a pipeline. For instance, platforms like Apache Airflow and Kubeflow help in orchestrating and managing workflows seamlessly.
I remember working on a project where integrating Apache NiFi allowed us to automate data ingestion, saving the team tons of manual labor. Some vital automation tools include:
- MLflow: For tracking experiments and managing the model lifecycle.
- TensorFlow Extended (TFX): For building end-to-end pipelines.
Scaling Machine Learning Pipelines for Big Data
As data volumes grow, scalability becomes a crucial factor in pipeline design. Using distributed computing frameworks like Apache Spark can greatly enhance the processing capabilities of machine learning pipelines. For instance, during my time working with large datasets, Spark allowed us to analyze data in parallel, significantly reducing computation time.
Key strategies for scaling include:
- Horizontal Scaling: Adding more machines to distribute the workload.
- Efficient Data Storage: Utilizing distributed storage solutions like Hadoop or cloud-based options.
By employing these techniques, teams can ensure their machine learning pipelines remain robust and responsive to the demands of big data, ultimately driving impactful insights.

Monitoring and Maintenance of Machine Learning Pipelines
Importance of Monitoring
As machine learning models are deployed and begin to process real-world data, continuous monitoring becomes critical. Monitoring ensures that models perform consistently and that any drift in data or model accuracy is promptly addressed. From my experience, failing to monitor effectively can lead to unexpected drops in performance, costing valuable time and resources.
Key reasons to monitor include:
- Detecting Model Drift: Identifying changes in data patterns over time.
- Performance Tracking: Keeping an eye on crucial metrics like accuracy and response time.
- Error Handling: Quickly identifying and resolving issues that may arise during execution.
Techniques for Pipeline Maintenance
Maintaining a machine learning pipeline requires regular upkeep to ensure optimal performance. Some effective techniques include:
- Automated Alerts: Setting up alerts for performance degradation.
- Version Control: Using tools like Git to manage model iterations effectively.
- Regular Audits: Periodically reviewing models and data quality.
In a recent project, conducting routine audits helped us catch a subtle data drift that would have led to outdated predictions if left unaddressed. With these maintenance techniques, teams can enhance their machine learning pipelines’ reliability and longevity.

Case Studies and Examples
Real-world Applications of Machine Learning Pipelines
Machine learning pipelines are making waves across various industries, showcasing their capability to solve complex problems efficiently. For instance, in healthcare, pipelines are used to analyze patient data, predict disease outbreaks, and personalize treatment plans. In one notable case, a healthcare startup used a machine learning pipeline to process enormous volumes of patient records, drastically improving diagnosis accuracy.
Some other standout applications include:
- Finance: Fraud detection systems leveraging real-time transaction analysis.
- Retail: Personalized marketing strategies based on consumer behavior.
Successful Implementation Stories
A great example of successful implementation is a major e-commerce company that automated its recommendation engine using a dedicated machine learning pipeline. By continuously monitoring customer interactions and feedback, they quickly adjusted their recommendations to match user preferences. This not only boosted customer engagement but also led to a remarkable increase in sales conversions.
These success stories highlight how harnessing machine learning pipelines effectively can empower organizations to unlock valuable insights and drive growth in innovative ways.
Challenges and Solutions in Machine Learning Pipeline Development
Common Challenges Faced
While developing machine learning pipelines, teams often encounter several challenges that can hinder progress. One of the most common issues is dealing with messy or inconsistent data, which can lead to inaccurate model predictions. Additionally, integrating various tools and frameworks into a cohesive pipeline can be a daunting task. I remember facing difficulties in maintaining communication between the data ingestion processes and model training stages during one of my projects, which created delays.
Some other prevalent challenges include:
- Model Drift: Changes in data patterns over time that can affect performance.
- Resource Management: Balancing computational resources efficiently.
Strategies to Overcome Challenges
Fortunately, there are effective strategies to address these challenges.
- Data Cleaning: Implementing rigorous data preprocessing practices to ensure quality.
- Regular Monitoring: Establishing continuous monitoring systems to quickly detect model drift.
- Modular Design: Creating a modular pipeline design that allows for easy integration of new tools.
For instance, adopting a modular framework during one project enabled our team to swap out components effortlessly, improving overall efficiency. By anticipating these challenges and leveraging effective strategies, teams can develop more resilient and successful machine learning pipelines.
Conclusion
Recap of Best Practices
As we wrap up our discussion on creating effective machine learning pipelines, it’s essential to highlight key best practices that can significantly enhance your workflow. Successful pipelines should incorporate:
- Comprehensive Data Preprocessing: Clean and prepare data to improve accuracy.
- Robust Feature Engineering: Craft new features that enhance model performance.
- Effective Monitoring and Maintenance: Continuously track model outputs for consistent results.
Putting these practices into action, as I did on several projects, can lead to more reliable and powerful machine learning applications.
Future Trends in Machine Learning Pipeline Development
Looking ahead, we can expect exciting developments in machine learning pipelines. Automation and AI-driven tools will become increasingly prevalent, streamlining processes further. Moreover, as the demand for real-time predictions rises, integration with cloud-based solutions and serverless architectures will become essential.
By staying informed about these trends, teams can position themselves to leverage the full potential of machine learning in impactful and innovative ways.
