

Introduction
Overview of Hyperparameter Optimization in Machine Learning
In the ever-evolving field of machine learning, hyperparameter optimization (HPO) serves as a crucial pillar that enhances model performance. Think of hyperparameters as the knobs and dials that you can tweak to refine your model—those settings that are not learned but must be specified beforehand. This includes variables like learning rates, the number of trees in a random forest, or the architecture of a neural network.
By optimizing these hyperparameters, data scientists can significantly improve the predictive capabilities of their machine learning models. One might wonder, “How to Optimize Hyperparameters in Machine Learning Models?” Understanding and implementing effective HPO techniques can be the game-changer in achieving the desired accuracy.
Significance of Optimizing Hyperparameters in Models
The significance of optimizing hyperparameters cannot be overstated. Properly tuned models boast:
- Improved Accuracy: Well-optimized parameters lead to better predictions.
- Robustness: A fine-tuned model is less likely to perform poorly on unseen data.
- Efficiency: Streamlined processes reduce training time and resource consumption.
Consider a scenario where a model demonstrates a 15% accuracy increase post-optimization; that’s the kind of impact effective hyperparameter tuning brings to the table. Embracing these practices can elevate not just individual projects, but also an organization’s overall data strategy.
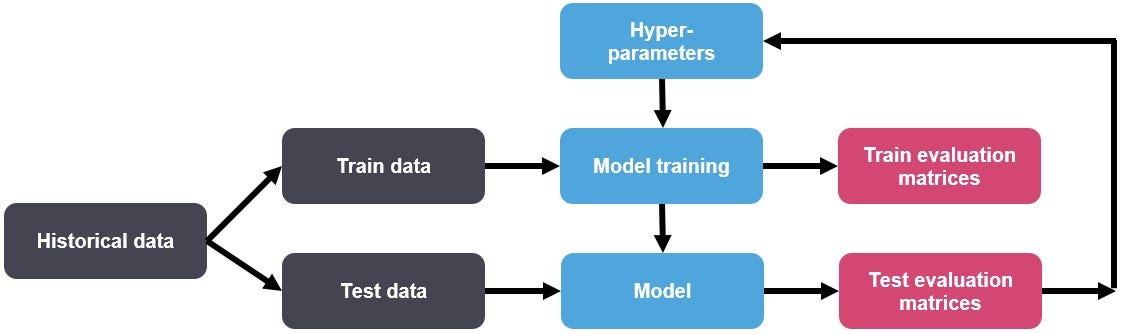
Understanding Hyperparameters
Definition and Role of Hyperparameters
To truly grasp how to elevate your machine learning models, it’s essential to first understand what hyperparameters are. Simply put, hyperparameters are the external configuration settings that control the learning process. They aren’t learned by the model during training—rather, they set the stage.
Consider the following key roles of hyperparameters:
- Model Complexity: Parameters like depth of a tree in decision trees can dictate how complex the model can become.
- Learning Rate: This crucial parameter defines how quickly the model adapts to the problem at hand.
- Regularization: Techniques to prevent overfitting, adjustable through hyperparameters, ensure that your model generalizes well.
Importance of Hyperparameter Tuning in Machine Learning
Now, why does hyperparameter tuning matter? Because the right set of parameters can drastically improve the performance of your model.
Here’s why tuning is indispensable:
- Maximized Performance: Models fine-tuned through optimization techniques can achieve higher accuracy.
- Prevention of Overfitting: Choosing the right regularization parameters can help keep the model robust to new data.
- Resource Efficiency: Efficient tuning reduces unnecessary computational costs and optimizes processing times.
By investing time in hyperparameter tuning, data scientists witness transformative results that can be the difference between a mediocre model and an exceptional one.
Techniques for Hyperparameter Optimization
As we continue to explore how to optimize hyperparameters in machine learning models, it’s vital to delve into the various techniques available. Each method has its unique advantages and can significantly impact the performance of your model. Let’s break down some widely-used approaches.
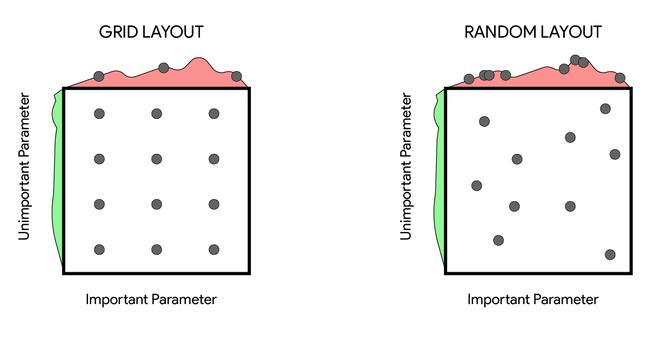
Grid Search Method
Grid Search is a straightforward yet effective technique. Imagine you have multiple hyperparameters, each with specific values. Grid Search exhaustively tests all combinations of these parameters.
Pros:
- Comprehensive and systematic.
- Easy to implement.
Cons:
- Can be computationally expensive.
- Time-consuming for large datasets.
Random Search Approach
Unlike Grid Search, Random Search selects a random combination of hyperparameters from the defined range. During a project I worked on, this method saved us considerable computation time while still yielding impressive results.
Pros:
- Reduced search time.
- Often outperforms Grid Search in practice.
Cons:
- No guarantee of finding the optimal combination.
Bayesian Optimization
Bayesian Optimization takes a probabilistic approach, prioritizing areas in the hyperparameter space that are more likely to yield better performance. It’s like having a savvy personal trainer who knows exactly when to push harder.
Pros:
- Efficient use of resources.
- Balances exploration and exploitation.
Cons:
- More complex to set up than other methods.
Genetic Algorithms
Inspired by the process of natural selection, Genetic Algorithms evolve hyperparameters over successive generations. During my experience with complex machine learning tasks, this approach yielded fantastic results, adjusting parameters dynamically.
Pros:
- Can escape local optima.
- Highly adaptable.
Cons:
- May require more computational power.
- Increased complexity in implementation.
Understanding these techniques equips data scientists with a toolbox to improve their model performance strategically. Choosing the right method can lead to groundbreaking results in any machine learning project.

Evaluation Metrics for Hyperparameter Tuning
As we embark on the journey to optimize hyperparameters in machine learning models, it’s crucial to assess how well our tuning efforts are actually paying off. This is where evaluation metrics come into play, acting as a compass that guides us toward better model performance. Let’s take a closer look at two essential components: accuracy and error metrics, as well as cross-validation techniques.
Accuracy and Error Metrics
Accuracy is often the first metric that comes to mind, especially in classification problems. It measures the proportion of correctly predicted instances. However, it’s essential to complement accuracy with error metrics such as:
- Precision: The ratio of true positive instances to the sum of true and false positives.
- Recall: The ability of a model to find all relevant cases within a dataset.
For instance, while optimizing an image classification model, one might prioritize precision if false positives could be particularly costly.
Cross-Validation Techniques
Cross-validation techniques add another layer of rigor to hyperparameter tuning. By dividing the dataset into multiple subsets, you can better assess how your model is likely to perform on unseen data. Common methods include:
- K-Fold Cross-Validation: Dividing the dataset into K equal parts and using one part for testing while the rest for training.
- Leave-One-Out Cross-Validation: A special case of K-Fold, where the number of folds equals the number of instances.
Using these techniques not only ensures that your model generalizes well but also provides a more reliable evaluation of hyperparameter choices. With the right metrics in hand, you can confidently steer your model toward peak performance.
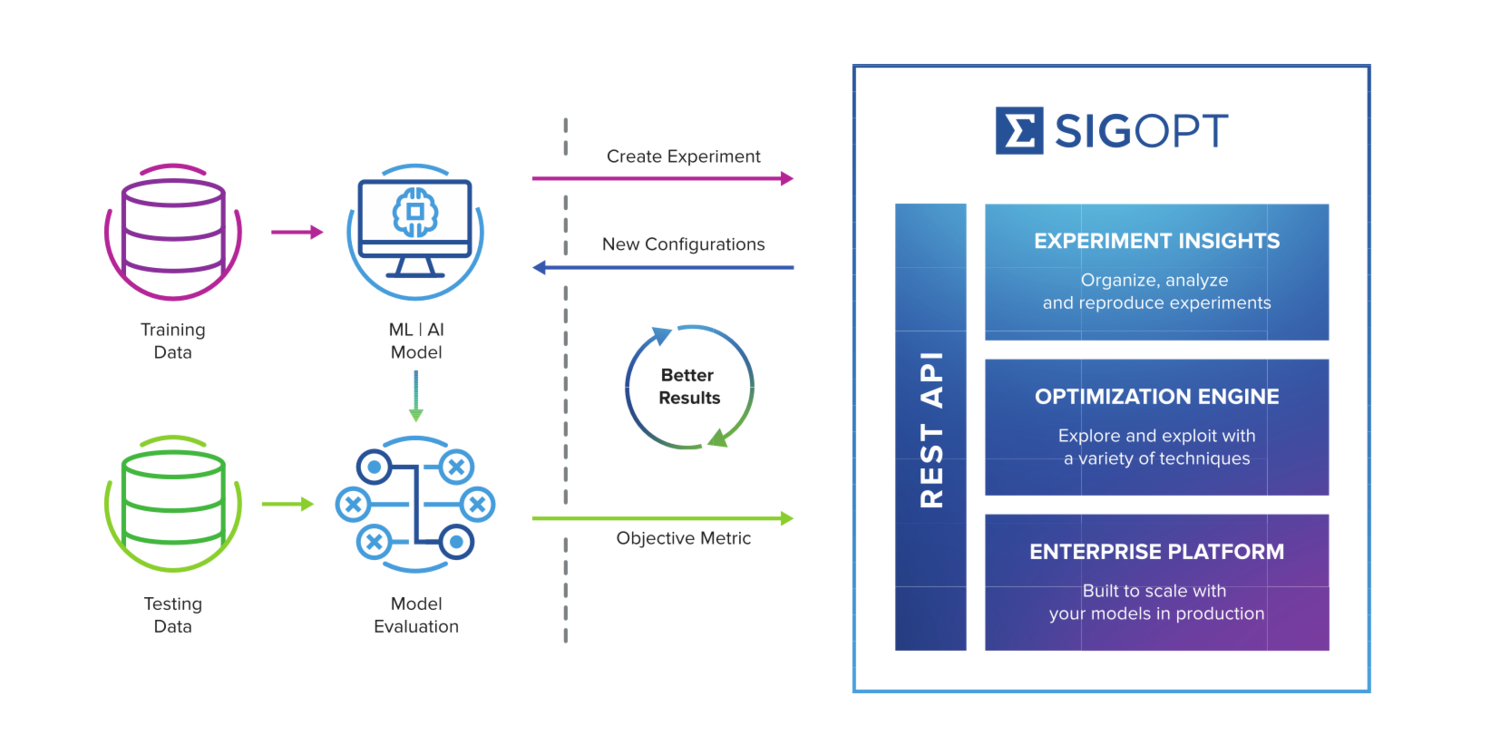
Automated Hyperparameter Tuning
As we venture into the user-friendly realm of automated hyperparameter tuning, it’s enthralling to witness how technology simplifies what can often feel like an arduous task. Automated Hyperparameter Optimization tools are designed to take over much of the manual effort involved, allowing data scientists to focus on what truly matters: interpreting results and applying insights effectively.
Introduction to Automated Hyperparameter Optimization Tools
Imagine a scenario where you don’t need to manually test every hyperparameter combination; automation does that tiresome work for you! These tools leverage sophisticated algorithms to efficiently navigate the hyperparameter space, significantly reducing training times while optimizing performance.
Overview of Popular Tools Like Hyperopt, Optuna, and AutoML
Here’s a quick overview of some popular automated hyperparameter optimization tools:
- Hyperopt: A powerful and flexible library that employs Bayesian optimization for hyperparameter tuning. It effectively explores the hyperparameter space, making it suitable for various applications.
- Optuna: Known for its ease of use and efficiency, Optuna allows users to define their optimization objectives and intelligently manage resource allocation. Its automatic pruning feature quickly discards poorly performing trials, saving time and computational resources.
- AutoML: A broader term encompassing a range of tools aimed at automating the end-to-end process of applying machine learning, including hyperparameter tuning, feature selection, and model building.
By incorporating these tools into your workflow, you can considerably enhance model performance while cutting down on tedious tasks, paving the way for a more efficient machine learning process.
Considerations and Challenges in Hyperparameter Optimization
As we deepen our understanding of hyperparameter optimization, it’s essential to acknowledge that this journey isn’t without its challenges. Factors such as data preprocessing and the ongoing battle between overfitting and underfitting play pivotal roles in determining the success of your models.
Data Preprocessing Impact
Data preprocessing serves as the bedrock upon which hyperparameter optimization stands. If the data isn’t cleaned and transformed appropriately, even the best-tuned hyperparameters will struggle to yield accurate results. Think of it as trying to bake a cake with expired ingredients: no matter how expertly you adjust the oven temperature, the outcome will never be satisfactory.
Key aspects to consider include:
- Normalization: Ensures that all features contribute equally, preventing certain hyperparameters from dominating.
- Handling Missing Values: Ignoring or poorly managing missing data can skew results and affect model performance significantly.
Overfitting and Underfitting Issues
The delicate balance of overfitting and underfitting is another prominent challenge. Overfitting occurs when a model learns noise in the training data, making it perform poorly on unseen data. Conversely, underfitting happens when a model is too simple to capture the underlying trends.
Factors to manage include:
- Regularization Techniques: Such as L1 and L2 regularization can help mitigate overfitting.
- Complexity Management: Continuously monitoring model complexity allows for better control over the trade-offs between fitting and generalization.
Being mindful of these considerations ensures a richer and more productive hyperparameter optimization experience, leading to robust and reliable machine learning models.

Case Studies and Practical Applications
As we explore the landscape of hyperparameter optimization, diving into real-world case studies and practical applications provides valuable insights into its transformative power. Many organizations are reaping significant benefits from well-tuned models, illustrating the tangible impact of optimization techniques.
Real-world Examples of Hyperparameter Optimization
Take, for instance, a telecommunications company aiming to reduce customer churn. By implementing hyperparameter tuning on their predictive models, they achieved a remarkable increase in accuracy from 75% to 90%. This allowed them to identify at-risk customers more effectively, leading to targeted retention strategies that saved millions in potential revenue.
In another example, a medical imaging startup used hyperparameter optimization to enhance the performance of their convolutional neural networks. With smarter tuning, they improved diagnosis accuracy on medical scans by 20%, making a substantial difference in patient care.
Impact of Hyperparameter Tuning on Model Performance
The impact of hyperparameter tuning is profound. Besides boosting accuracy, it often contributes to:
- Faster Training Times: Efficient tuning leads to quicker model development cycles.
- Enhanced Generalization: Well-optimized models perform better not just on training data but also on unseen datasets.
Consider this: tuning your model’s hyperparameters can mean the difference between a mediocre and extraordinary performance. Investing in these strategies means investing in the future success of your machine learning endeavors.

Conclusion and Future Perspectives
As we wrap up our exploration into hyperparameter optimization, it’s evident that fine-tuning these critical parameters is not just a technical task but a strategic necessity for achieving optimal model performance.
Summary of Key Strategies for Effective Hyperparameter Optimization
From our discussions, several key strategies emerge for effective hyperparameter optimization:
- Utilize Automated Tools: Embrace tools like Hyperopt, Optuna, and AutoML to simplify the tuning process and save valuable time.
- Focus on Data Preprocessing: Always ensure your data is clean and well-prepared to maximize the efficiency of your tuning efforts.
- Balance Overfitting and Underfitting: Regularization techniques can be your best friend in maintaining that delicate balance for precise predictions.
These strategies, when applied thoughtfully, can lead to substantial improvements in your model’s efficacy.
Emerging Trends in Hyperparameter Tuning Research
Looking ahead, emerging trends in hyperparameter tuning are gaining traction. Innovations in meta-learning, where models learn to optimize hyperparameters based on past experiences, show great promise. Furthermore, advancements in reinforcement learning-based optimization techniques could revolutionize the way we approach this challenge.
As the field evolves, staying abreast of these trends will be critical for data scientists aiming to push the boundaries of machine learning performance. Together, we can embrace a future where hyperparameter optimization is more efficient, effective, and integral to the success of machine learning projects.
