

Introduction
Overview of Feature Engineering
Feature engineering is the art and science of transforming raw data into meaningful attributes that can boost the performance of machine learning models. It encompasses various techniques aimed at identifying, manipulating, and creating features that add value to the dataset at hand. Think of it as the preparation of ingredients before cooking; the right combination and measurements make all the difference.
To illustrate, consider a retail dataset that includes customer transactions. Raw data might include fields like transaction time, item categories, and prices. Feature engineering could involve deriving new features such as “day of the week,” “total spend,” or “repeat purchase flag,” enhancing the model’s ability to recognize patterns.
Importance of Feature Engineering in Machine Learning
The role of feature engineering in improving machine learning accuracy cannot be overstated. It directly influences the model’s ability to learn and generalize:
- Better features lead to improved model performance.
- Reduces training time by simplifying the learning process.
- Helps avoid overfitting by ensuring that features are relevant.
In the competitive landscape of AI, investing effort in effective feature engineering—just like a chef perfecting a signature dish—often yields the best results.
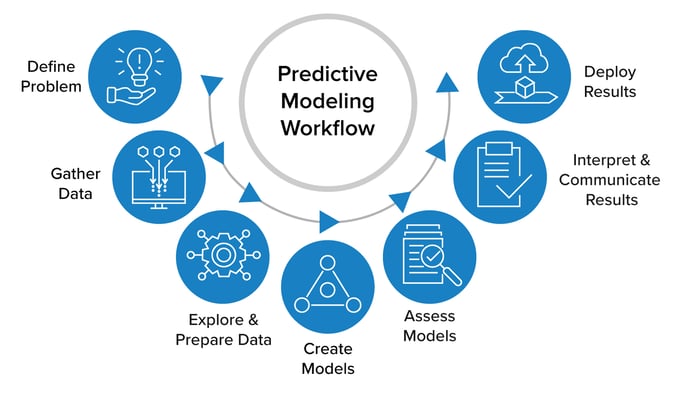
Fundamentals of Feature Engineering
Definition and Purpose of Feature Engineering
Building on the essential role of feature engineering in machine learning, it’s important to define what it actually entails. Feature engineering refers to the process of selecting, modifying, or creating variables (features) that can enhance the predictive performance of a model. It essentially transforms data into a format that is more suitable for machine learning algorithms.
The purpose of this craft is clear: empower models to make more accurate predictions and extract valuable insights from the data. When done correctly, feature engineering can:
- Highlight underlying relationships.
- Reduce noise and irrelevant information.
- Address data quality issues, such as missing values.
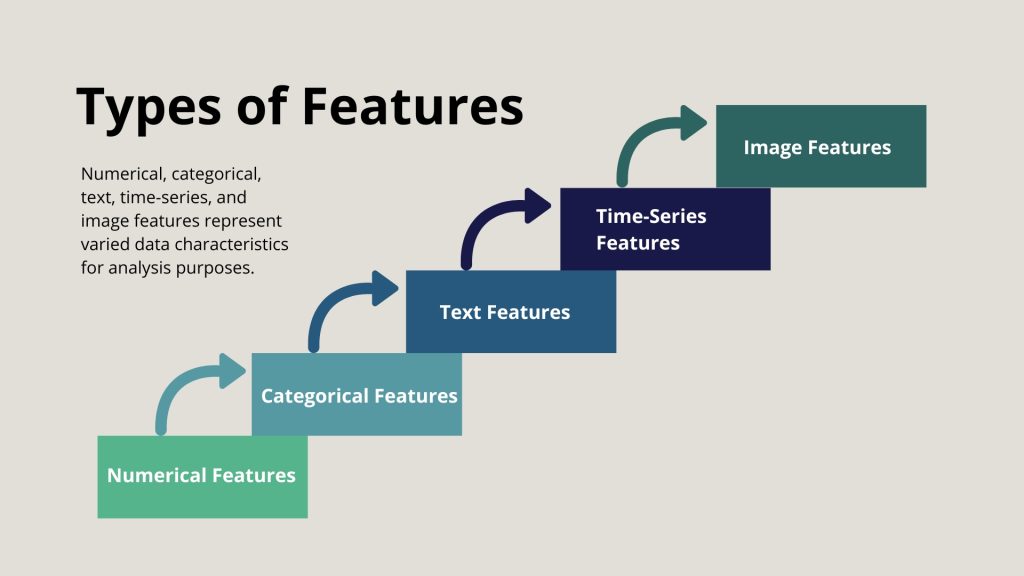
Types of Features in Machine Learning
Understanding different types of features is crucial for any data scientist or machine learning practitioner. Features are typically categorized into:
- Numerical Features: Continuous values, such as prices or age.
- Categorical Features: Discrete categories, like gender or brand names.
- Ordinal Features: Categorical data with an intrinsic order, such as ratings (e.g., 1-5 stars).
By mastering these various types of features, practitioners can tailor their feature engineering approaches to best fit the specific requirements of their models, leading to improved accuracy and reliability.
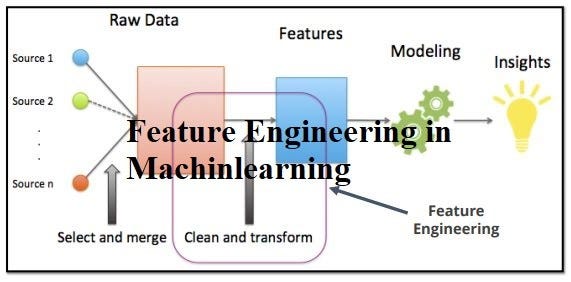
Techniques for Feature Engineering
Missing Value Imputation
Continuing the exploration of feature engineering, one of the most critical techniques is missing value imputation. When dealing with real-world datasets, missing values are almost inevitable. For instance, imagine analyzing customer feedback where some responses are incomplete. To manage this, practitioners can use techniques like:
- Mean/Median Imputation: Filling missing values with the average or median of the column.
- K-Nearest Neighbors (KNN): Predicting missing values based on similar instances.
Encoding Categorical Variables
Next is encoding categorical variables, which is essential for transforming textual data into numerical formats that models can effectively analyze. For instance, if you have a dataset with a “color” feature (red, blue, green), using techniques like:
- One-Hot Encoding: Creates binary columns for each category.
- Label Encoding: Assigns a unique integer to each category.
This allows the model to understand categorical relationships better.
Feature Scaling
Feature scaling is another vital step, especially when working with algorithms sensitive to feature magnitudes. Techniques such as:
- Standardization (Z-score normalization): Centers the data around zero.
- Min-Max Scaling: Rescales values into a specified range, typically [0, 1].
Scaling ensures that no single feature dramatically skews the model’s learning process.
Feature Selection
Finally, feature selection involves identifying and retaining the most important features. This can improve model performance and reduce complexity. Common methods include:
- Recursive Feature Elimination (RFE): Systematically removes features to find the optimal number of variables.
- Feature Importance from Trees: Utilizing tree-based models to rank feature importance.
By implementing these techniques, practitioners can significantly enhance their machine learning models, paving the way for improved accuracy and efficiency.

Advanced Feature Engineering Methods
Polynomial Features
Building on the foundational techniques of feature engineering, advanced methods can take your model performance to new heights. One such method is generating polynomial features. This technique involves creating new features by raising existing variables to a certain power. For instance, if you have a single feature representing age, you could introduce ( text{age}^2 ) or ( text{age}^3 ) as new features to capture non-linear relationships and interactions that a linear model might overlook.
Benefits of Polynomial Features:
- Captures complex patterns.
- Enhances model flexibility.
Interaction Features
Another powerful technique is crafting interaction features. This method focuses on combining two or more features to discover relationships between them. For example, combining “age” and “income” could reveal insights about spending habits specific to different age groups. Interaction terms allow the model to capture multi-dimensional patterns that are otherwise undetectable.
Feature Extraction using Dimensionality Reduction
Lastly, feature extraction via dimensionality reduction techniques like Principal Component Analysis (PCA) transforms high-dimensional data into a lower-dimensional space. This process simplifies datasets by identifying the most influential features while reducing noise.
Advantages of Dimensionality Reduction:
- Decreased computational costs.
- Enhanced model performance by eliminating redundant features.
Employing these advanced methods can lead to models that not only perform better but also provide clearer insights into complex datasets.

Evaluation and Validation of Engineered Features
Cross-Validation
As we delve deeper into evaluating engineered features, one of the most important techniques is cross-validation. This method helps ensure that our models are not just performing well on training data but are also robust when tested on unseen data. The concept is simple: by dividing the dataset into multiple subsets or “folds,” the model is trained on a portion of the data while validating on the others.
The benefits of cross-validation include:
- Reduced Risk of Overfitting: By validating the model consistently, you can identify whether it’s too tailored to the training set.
- More Reliable Performance Metrics: It provides a clearer picture of how the model will likely perform in real-world scenarios.
Impact of Feature Engineering on Model Performance
Now, let’s discuss the tangible impact of feature engineering on model performance. Thoughtfully engineered features can dramatically improve accuracy, speed, and interpretability. For instance, a practical example is transforming a basic dataset into one enriched with interaction and polynomial features.
- Improved Predictions: Well-crafted features enable models to capture intricate patterns.
- Increased Model Efficiency: Reduced dimensionality translates to shorter training times.
Overall, the evaluation of engineered features through methods like cross-validation allows data professionals to robustly assess how these enhancements influence model performance, making feature engineering an invaluable part of the machine learning pipeline.
Case Studies and Practical Applications
Feature Engineering in Natural Language Processing
Moving towards practical applications, let’s explore how feature engineering plays a crucial role in Natural Language Processing (NLP). In NLP tasks like sentiment analysis, feature engineering can make or break model performance. Techniques like tokenization, where sentences are broken down into words or phrases, along with n-grams, allow the model to capture contextual nuances.
For example, if analyzing customer reviews, phrases like “highly recommend” can convey more sentiment than just individual words. By employing methods such as:
- TF-IDF (Term Frequency-Inverse Document Frequency): Highlights significant words in a document.
- Word Embeddings (like Word2Vec or GloVe): Captures semantic meaning through dense vectors.
These engineered features enable models to derive meaning and context effectively, leading to more accurate sentiment predictions.
Feature Engineering for Image Recognition
Now, let’s pivot to image recognition, where feature engineering techniques are also vital. In this domain, features can be derived from pixel intensity, shapes, and textures. For instance, using techniques like:
- Edge Detection: Identifies and enhances shapes in images.
- Histogram of Oriented Gradients (HOG): Extracts directional gradients, often used in object detection tasks.
By transforming raw pixel data into meaningful features, models gain the ability to recognize and categorize images with greater accuracy. Thus, whether it’s analyzing text or images, effective feature engineering lays the groundwork for achieving impressive results across various machine learning applications.
Challenges and Considerations in Feature Engineering
Overfitting
As we continue our journey through feature engineering, it’s vital to address some challenges that can arise. One significant concern is overfitting. When a model becomes too specialized to the training data, it captures noise rather than underlying patterns, resulting in poor performance on new, unseen data.
For instance, if you engineer too many polynomial features for a simple linear model, you can unintentionally create a model that fits the training dataset perfectly but fails when it encounters real-world scenarios.
To mitigate overfitting, consider:
- Regularization Techniques: L1 (Lasso) and L2 (Ridge) can help constrain feature coefficients.
- Limit Feature Creation: Be judicious, focusing on the most significant features.
Computational Complexity
Another challenge lies in computational complexity. As you engineer more features, the time and resources required to train the model can skyrocket. Imagine working with a large dataset and creating hundreds of interaction terms; you may quickly find your processing power stretched thin.
To tackle this, adopt strategies such as:
- Dimensionality Reduction: Techniques like PCA can simplify your feature set while retaining essential information.
- Efficient Algorithms: Using algorithms designed to handle larger datasets can significantly improve processing times.
By being aware of these challenges—overfitting and computational complexity—data practitioners can better navigate the feature engineering landscape and build more robust machine learning models.
Future Trends and Innovations in Feature Engineering
AutoML for Feature Engineering
As we look ahead in the field of feature engineering, one of the most promising trends is the rise of AutoML (Automated Machine Learning). AutoML platforms are designed to automate the tedious process of model selection and feature engineering, making machine learning more accessible to non-experts. Imagine a scenario where you can simply upload your dataset, and the AutoML tool intelligently identifies and engineers features, selects appropriate models, and optimizes hyperparameters.
The benefits of AutoML include:
- Time Savings: Reduces the manual effort involved in crafting features.
- Diverse Method Application: Automatically applies various feature engineering techniques and benchmarks their performance.
Integration of Feature Engineering in Neural Networks
Another exciting trend is the integration of feature engineering within the architecture of neural networks. Traditionally viewed as “black boxes,” neural networks are now evolving to incorporate feature engineering steps in their layers. For instance, convolutional layers can automatically extract edge and texture features from images without prior manual feature engineering.
Key advancements in this integration may lead to:
- Better Interpretability: Understanding how features evolve through layers.
- Enhanced Model Performance: By allowing the network to focus on relevant feature extraction while learning.
Overall, these future trends signal a shift towards more automated, efficient, and effective feature engineering strategies that will undoubtedly shape the landscape of machine learning in the coming years.
Conclusion
Summary of the Role of Feature Engineering
As we wrap up our exploration into feature engineering, it’s clear that this critical process acts as the backbone of successful machine learning projects. By transforming raw data into meaningful features that adequately represent underlying patterns, practitioners can unlock the true potential of their models. From addressing missing values to employing advanced techniques like polynomial and interaction features, the art of feature engineering is ever-evolving.
To put it simply:
- Feature engineering enhances model interpretability.
- It helps streamline the modeling process and reduces complexity.
- High-quality features lead to better predictions.
Potential Impact on Machine Learning Accuracy
The potential impact of feature engineering on machine learning accuracy cannot be overstated. Properly engineered features can drastically improve a model’s performance, making the difference between a mediocre and an exceptional model. For example, meticulous feature selection may reduce overfitting and enhance generalization, while effective scaling can accelerate convergence.
In essence, dedicating time and effort to feature engineering can yield compounding returns, resulting in models that are not only accurate but also robust and reliable. The journey may require patience, but the fruits of well-crafted features are undeniably rewarding in the quest for machine learning excellence.
