
Introduction
Evolution of Machine Learning
Machine learning has come a long way since its inception. Initially, it gained momentum in the 1950s, primarily through theoretical advancements and explorations in artificial intelligence (AI). The initial phase consisted of simple algorithms designed to enable machines to learn from data. Over the years, this field has evolved significantly, marked by breakthroughs like the introduction of decision trees, support vector machines, and more recently, deep learning techniques.
Some key milestones in the evolution of machine learning include:
- 1950s: Emergence of early AI concepts and the first neural networks.
- 1980s: The rise of backpropagation for training neural networks.
- 2000s: Increased computational power and the availability of large datasets, leading to the boom of machine learning applications.
Each phase of evolution shifted the capability of machines from basic pattern recognition to complex decision-making processes.
Impact of Machine Learning on Modern Applications
The influence of machine learning is pervasive in today’s world, transforming 21st-century applications in various domains. From healthcare to finance, the integration of machine learning technologies has streamlined processes and improved efficiency.
For instance, in healthcare, machine learning algorithms analyze vast amounts of patient data, assisting doctors in diagnosing diseases more accurately than ever before. In finance, algorithms predict stock market trends, optimizing investment strategies based on past performance data.
Key areas positively impacted by machine learning include:
- E-commerce: Personalized recommendations enhancing customer experience.
- Transportation: Routing and logistics solutions that improve delivery times.
- Social Media: Enhanced content delivery through targeted advertising.
These advancements illustrate how harnessing the power of machine learning is not just a trend; it’s a paradigm shift altering the fabric of numerous industries. The journey of machine learning is not only exciting but also crucial for future innovations that will continue shaping our society.

Foundations of Machine Learning
Understanding Algorithms and Models
As machine learning continues to make waves in technology and business, it’s essential to grasp its core components—algorithms and models. Simply put, an algorithm is a step-by-step procedure that helps computers solve problems, while a model is the result of applying an algorithm to data.
Imagine teaching a child to recognize animals through a series of pictures. You would show them different animals (data) while explaining the characteristics of each type. Over time, the child forms a mental model. Similarly, when we use machine learning algorithms, we enable computers to learn from data and create models that can make predictions or classify new data effectively.
Some common algorithms include:
- Linear Regression: Used for predicting continuous values.
- Decision Trees: Great for classification tasks.
- K-Means Clustering: Used for unsupervised learning tasks.
Data Preprocessing and Feature Engineering
Before we dive deeper into model training, data preprocessing and feature engineering play crucial roles in the machine learning pipeline. It’s much like preparing ingredients before cooking a masterpiece in the kitchen.
Data preprocessing ensures that the data is clean, consistent, and usable. This step might involve:
- Handling Missing Values: Filling in gaps or removing incomplete data points.
- Normalization: Adjusting values to a common scale without distorting differences in the ranges.
Once the data is prepared, feature engineering comes into play. This involves selecting and transforming the data into meaningful representations to improve model performance. For example, if working with a dataset containing date information, converting it into separate features like the day of the week and month can provide valuable insights.
These foundational steps not only enhance data quality but also ensure that machine learning models can harness the power of machine learning effectively. Without them, even the best algorithms can yield subpar results, rendering the machine learning journey less fruitful.
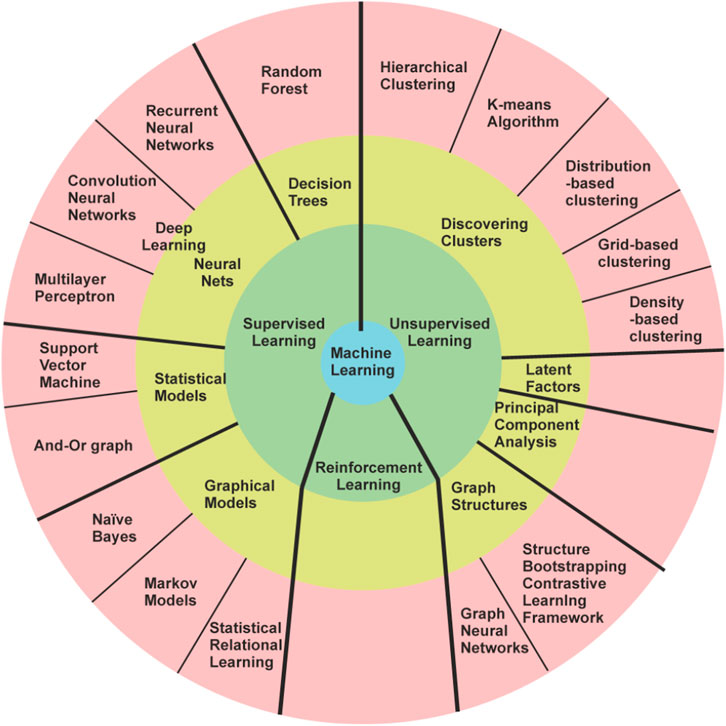
Machine Learning Techniques
Supervised Learning
Diving deeper into the realm of machine learning, one of the primary techniques is supervised learning. This approach involves training a model on labeled data, meaning that the input data is paired with the correct output. It’s a bit like having a teacher guide a student, providing feedback as they learn to make predictions or classifications.
Some prevalent supervised learning algorithms include:
- Linear Regression
- Logistic Regression
- Support Vector Machines
Regression
Within supervised learning, regression techniques are particularly useful for predicting continuous outcomes. For example, if someone wanted to forecast house prices based on features like size, location, and condition, regression models can identify patterns within the data to make informed estimates.
The main types of regression include:
- Simple Linear Regression: Predicting outcomes using a single feature.
- Multiple Linear Regression: Involving multiple features for a more accurate estimate.
Classification
On the other hand, classification tasks are aimed at assigning inputs to predefined categories. Think of it as sorting your emails into folders based on their subject—each email belongs to a specific category (like promotions or work-related). Common classification algorithms include:
- Decision Trees
- Random Forests
- K-Nearest Neighbors
Unsupervised Learning
Moving on to unsupervised learning—this technique is like a student exploring without a guide. Here, algorithms analyze unlabeled data and uncover hidden patterns or structures without provided answers.
Clustering
One of the most popular methods within unsupervised learning is clustering. This groups similar data points together, helping to discover natural groupings. For example, businesses use clustering to segment their customer base into distinct groups based on purchasing behavior.
Dimensionality Reduction
Another key aspect of unsupervised learning is dimensionality reduction, which simplifies data by reducing the number of variables. It’s akin to condensing your wardrobe to your favorite outfits—keeping it manageable while retaining style. Techniques like PCA (Principal Component Analysis) help retain important information while minimizing complexity.
Reinforcement Learning
Lastly, we have reinforcement learning, which mimics a trial-and-error approach. The model learns by interacting with its environment and receiving feedback in the form of rewards or penalties, much like training a pet to do tricks. This technique is gaining traction, especially in areas like robotics and gaming, where decision-making in dynamic environments is crucial.
These various techniques form the backbone of how machines learn. By understanding and applying these methods correctly, practitioners can harness the power of machine learning to tackle real-world challenges effectively.

Deep Learning and Neural Networks
Basics of Deep Learning
As we advance further into the realm of machine learning, deep learning emerges as a sophisticated subset, characterized by its use of neural networks with multiple layers. Think of deep learning as an advanced form of machine learning, capable of discovering intricate patterns in vast amounts of data. The “depth” in deep learning refers to the number of layers within these neural networks, which allows the algorithm to learn from data at different levels of abstraction.
Deep learning has been pivotal in solving complex problems in areas such as image and speech recognition, natural language processing, and more.
Some key features of deep learning include:
- Automatic Feature Extraction: Unlike traditional methods, deep learning automatically identifies relevant features from raw data.
- Scalability: It performs exceptionally well with large datasets, leveraging high computational power effectively.
Convolutional Neural Networks
One of the most popular architectures in deep learning is the Convolutional Neural Network (CNN). Primarily used for processing structured grid data like images, CNNs excel in recognizing patterns. They mimic how the human visual system works by applying convolutional layers.
When you load a photo into a CNN, it scans the image through filters to identify features like edges, textures, and shapes. This hierarchical approach results in impressive accuracy for tasks like:
- Image classification
- Object detection
- Facial recognition
Recurrent Neural Networks
On the flip side, we have Recurrent Neural Networks (RNNs), designed for sequential data—think of them as memory-empowered neural networks. RNNs excel in applications such as language modeling and time-series prediction because they maintain a ‘memory’ of previous inputs.
For example, when predicting the next word in a sentence, an RNN is trained to consider not only the current word but also the context provided by prior words. Features of RNNs include:
- Long Short-Term Memory (LSTM): An advanced form of RNN that tackles the challenge of short-lived memory, making them more effective for complex tasks.
- Applications: Used extensively in speech recognition and sentiment analysis.
Together, CNNs and RNNs represent the cutting-edge of deep learning, showcasing its ability to address complex challenges across various industries. By leveraging these neural network architectures, innovators are pushing the boundaries of what is possible in artificial intelligence today.
Implementing Machine Learning Models
Choosing the Right Model
Building a successful machine learning project hinges heavily on the choice of the right model. Just like selecting the right tool for a job, the model needs to align with the specific task at hand. Key considerations include the nature of the data, the problem to be solved, and performance metrics.
For instance, if you’re dealing with a classification task, models like Decision Trees or Support Vector Machines may be ideal. Conversely, for regression tasks, Linear Regression or Random Forest may be more appropriate. Here are a few guiding questions to help choose the right model:
- What is the size and quality of your dataset?
- Is the output categorical or continuous?
- What is the desired interpretability of the model?
Training and Evaluation of Models
Once the right model is chosen, the next step is training and evaluating it. Training involves feeding the model with data, allowing it to learn the underlying patterns. When training a model, it’s essential to split your dataset into training and testing sets to validate performance accurately.
Evaluation metrics, such as accuracy, precision, and recall, help assess how well the model performs. Imagine trying to bake a cake without a taste test; similarly, evaluating a model ensures you’re on the right track to achieving effective predictions.
Hyperparameter Tuning
Finally, hyperparameter tuning is the process of optimizing certain parameters that govern the learning process, influencing how the model behaves. It’s like fine-tuning the settings on a coffee machine to get the perfect brew—small adjustments can lead to significant improvements in performance.
Common techniques for hyperparameter tuning include:
- Grid Search: Exhaustively searching through a predetermined set of parameters.
- Random Search: Sampling a wide range of parameters randomly.
- Cross-Validation: Assessing model performance using a portion of the data not involved in training.
By focusing on these aspects—choosing the right model, training effectively, and tuning hyperparameters—practitioners can significantly enhance model performance. Implementing machine learning models with these strategies is essential for unlocking their potential and achieving meaningful results.
Applications of Machine Learning
Image and Speech Recognition
Transitioning into the world of applications, machine learning is revolutionizing the way we interact with technology, particularly in image and speech recognition. These technologies delve into the capabilities of computers to interpret visual data and understand spoken language.
For instance, when you upload a photo to social media, algorithms detect faces and suggest tags—this is image recognition at work! It relies on deep learning models, such as Convolutional Neural Networks (CNNs), to analyze pixel patterns and features. Similarly, speech recognition applications, like virtual assistants (think Siri or Alexa), utilize machine learning to comprehend and respond to voice commands effectively.
Key benefits of these applications include:
- Enhanced accessibility for individuals with disabilities.
- Improved customer service through voice-activated assistance.
- Automatic tagging and organization of visual content.
Natural Language Processing
Natural Language Processing (NLP) is another impressive application that allows machines to understand and interpret human language. Imagine you’re texting a friend, and your device suggests the next word—NLP makes that possible. By employing techniques like tokenization and sentiment analysis, NLP leverages algorithms to parse and understand text, enabling applications such as:
- Chatbots providing customer support.
- Language translation services, like Google Translate.
- Sentiment analysis for gauging public opinion on social media.
Recommender Systems
Finally, recommender systems harness machine learning to personalize user experiences across various platforms. Whether you’re watching a Netflix series or shopping on Amazon, these systems suggest content or products based on user preferences and behavior.
The magic behind recommender systems can be categorized into two primary types:
- Collaborative Filtering: Analyzing user interactions and behaviors to recommend items similar to what others liked.
- Content-Based Filtering: Offering suggestions based on item features, such as genres or keywords.
These applications exemplify how machine learning is transforming industries and enhancing user interaction, making technology more intuitive and responsive. As we harness the power of machine learning, the potential for innovative applications seems limitless, reshaping our daily lives in remarkable ways.
Ethical Considerations in Machine Learning
Bias and Fairness
As the applications of machine learning expand, so do the ethical considerations surrounding its implementation. One of the primary concerns is bias and fairness within algorithms. If the training data reflects societal biases, the model may perpetuate or even amplify these biases when making decisions.
For instance, if a hiring algorithm is trained on historical employment data that favors certain demographics, it may inadvertently skew results against other groups. This can lead to unfair treatment in hiring practices, casting a shadow over the intended benefits of using such technology.
To tackle these issues, practitioners should focus on:
- Diverse Datasets: Ensuring training data encompasses a wide range of demographics.
- Regular Audits: Continuously assessing models for biases and making adjustments accordingly.
- Transparency: Being open about algorithmic decision-making processes to foster trust.
Privacy and Security
Alongside bias, privacy and security emerge as significant ethical considerations in machine learning. As more data is collected to train models—often containing sensitive information—protecting individual privacy becomes paramount.
Imagine using a health app that monitors your habits and activities. If the data isn’t adequately protected, it poses risks of unauthorized access or misuse. Here are some key practices to enhance privacy and security:
- Data Anonymization: Removing personally identifiable information to safeguard user privacy.
- Robust Security Measures: Implementing encryption and securing data storage systems against breaches.
- Regulatory Compliance: Adhering to regulations such as GDPR to ensure ethical data handling practices.
These ethical considerations are not just abstract concepts; they have real-world implications that can significantly affect individuals and society. By prioritizing bias reduction and safeguarding privacy, the field of machine learning can move towards more ethical, fair, and secure solutions, ultimately benefiting everyone involved.

Future Trends in Machine Learning
Explainable AI
As we look ahead in the realm of machine learning, one of the most significant trends is the development of Explainable AI (XAI). With machine learning models becoming increasingly complex, understanding how they make decisions is paramount for users and stakeholders. Imagine relying on a model to predict credit scores without knowing the factors influencing its decision—this lack of transparency can undermine trust.
Explainable AI addresses this challenge by providing insights into the decision-making process of algorithms. Some key features include:
- Model Interpretability: Making results understandable, such as highlighting which features most influenced a specific decision.
- User Trust: By providing transparency, users feel more confident in adopting AI solutions.
- Regulatory Compliance: As laws evolve, businesses can ensure their systems meet the standards for accountability.
By focusing on explainability, the future of machine learning can cater to both technological advancement and user comfort.
Federated Learning
Another exciting trend on the horizon is Federated Learning, a paradigm shift in how machine learning models are trained. This approach allows models to learn from data distributed across various devices without needing to centralize that data. Think about a smartphone app that trains a predictive model on users’ devices, enhancing privacy.
Benefits of federated learning include:
- Enhanced Data Privacy: Sensitive data remains on users’ devices, reducing exposure to breaches.
- Reduced Latency: Localized training leads to faster model updates by leveraging available device resources.
- Improved Personalization: Models can be tailored based on local data, offering a more personalized experience to users.
As we embrace these forward-looking trends, the future of machine learning will continue to evolve, pushing boundaries while advocating ethical standards and user-centric approaches. Explainable AI and federated learning are just the beginning of a more thoughtful and innovative landscape in machine learning, paving the way for more responsible technology deployment.

Challenges in Machine Learning Implementation
Data Quality and Quantity
As we traverse the landscape of machine learning, one of the significant challenges practitioners face is ensuring the quality and quantity of the data. Data serves as the backbone of any machine learning model—without it, the whole structure collapses. Imagine trying to bake a cake with expired ingredients; the outcome would be far from delicious, just like a poorly trained model can lead to inaccurate predictions.
Quality issues can arise from:
- Inaccurate Data: Mistakes in data entry or collection processes can introduce errors.
- Missing Values: Incomplete datasets can skew results and lead to misleading insights.
Quantity is just as critical; models need enough data to learn effectively. Inadequate data can result in overfitting, where the model performs well on training data but struggles with new, unseen examples. Therefore, investing time in data cleansing and augmentation is crucial for successful machine learning implementation.
Interpretable Models
The second challenge relates to the interpretability of models, particularly as complexity increases. While deep learning models may achieve high accuracy, they often act as “black boxes,” making it difficult to understand how decisions are made. This opacity can be problematic, especially in sensitive areas like healthcare or finance, where decisions can significantly impact individuals’ lives.
Key considerations include:
- Balancing Complexity and Interpretability: Striking a balance between a powerful model and one that stakeholders can understand.
- Available Techniques: Employing methods such as LIME (Local Interpretable Model-agnostic Explanations) that help elucidate model predictions.
Tackling these challenges is essential for the successful deployment of machine learning technologies. By focusing on data quality and fostering model interpretability, practitioners can create more reliable, trustworthy systems, ultimately leading to better decision-making and more impactful applications.

Conclusion
Recap of Machine Learning Advancements
As we bring our exploration of machine learning to a close, it’s essential to reflect on the incredible advancements we’ve witnessed in this field over the years. From its early days of simple algorithms to the rise of deep learning and neural networks, machine learning has dramatically enhanced various applications.
We have touched on vital areas such as:
- Image and Speech Recognition: Making technology more intuitive and accessible.
- Natural Language Processing: Enabling machines to understand and interpret human language.
- Recommender Systems: Creating personalized experiences across platforms.
These advancements are not just technical milestones; they are pivotal in shaping how we interact with technology and improve our daily lives.
Future Outlook
Looking ahead, the horizon is filled with promising trends such as Explainable AI and Federated Learning, indicating a shift towards more ethical and user-focused applications of machine learning. Organizations will benefit from adopting practices that emphasize data quality and interpretability to gain stakeholder trust and better understand their models’ decision-making processes.
As machine learning continues to evolve, the potential applications are virtually limitless. The combination of technological prowess and a commitment to ethical practices will ensure that machine learning remains an impactful force for positive change in society. Together, we can harness the power of machine learning to address complex global challenges, leading to a brighter, more innovative future.
